
定期存档
目录
- IOS项目涉及到的开发知识(20180510)
- PC工程配置相关知识(20180710)
- IPC(20180806)
- $\alpha$-Blending(20180829)
- 练习list(20181101)
- 工作中涉及到的操作
- conda and virtualbox
- Keras相关的经验
- Tensorflow
- Lasagne
- conda and virtualbox
- 深度学习开发环境
IOS项目涉及到的开发知识20180510
- 1. ios工程配置相关知识、2. 属性和实例变量、3. extern、static、const、4. grammar1、5. OC与C++混编、6. ios的黑魔盒、7. viewDidLoad, viewDidAppear执行顺序、8. Singleton与多线程、9. NSData、10. iOS 文件目录、11. Runloop、12. ios消息机制
1. ios工程配置相关知识
一些名词:
- App ID(Prouct ID): 标识一个或一组App, 与Xcode中的Bundle Identifier一致的或匹配的.
- CA发布数字证书用以区分通讯各方身份信息.
- 数字证书: 包含: 公开秘钥[相当于公章]、名称、数字签名; 具有实效性[只在特定的时间段内有效]
- 根证书: 最根上的证书(如户籍证明), 是信任链的起点.
- ios证书: 验证App内容是完整、可靠、合法的. 分两类: Development、Production.
- Development certificate: 用来开发和调试应用程序.
- Production certificate: 用于分发App.
- 普通个人开发账号可注册两个Development certificate和两个Development certificate.
ios app开发调试过程中的开发证书:
- ios app开发证书的根证书是Apple Worldwide Developer Relations Certification Authority, 他们之间的关系好比于身份证之于户籍.
- 证书申请: keychain生成CSR[包含开发者身份信息], 同时新增一对public/private key pair. public key随app走, 对app签名进行教研, private key 保存在keychain Access[本地], 以防假冒.
- Apple Worldwide Developer Relations Certification Authority使用private key对CSR中的public key和开发者身份信息进行加密签名生成数字证书并记录在案.
证书的安装:
- 从Apple Member Center下载双击、Xcode添加开发账号自动同步证书和配置文件.
- build settings > code signing > 配置开发证书.
Provisioning profile:
- 打包或真机运行app, 需要: 指明App ID并验证是否于Bundle ID匹配、签名[用证书的私钥签名, 以确定App合法、安全、完整]、确认设备是否授权运行这个app.
- 而Provisioning profile(pp)涵盖上面提到的: App ID、签名、设备, 它将这三项打包在一起方便在调试和打包时使用, 因此只要在不同的情况下选择不同的pp就行了.
- pp分为: Development和Distribution两类, 后者主要用于提交到App Store, 这里就不指定设备了.
- 所有的pp文件被防止在~/Library/MobileDevice/Provisioning Profiles
开发版pp文件中字段的含义:
- DeveloperCertificates: 必须这个列表里的证书签名, 否则一定codeSign fail.
- ProvisionedDevices: 这里配置了设备
Team PP:
- 每个Apple开发者账号都对应一个唯一的Team ID.
App Group
- ios8以后出现了App Extension, containing App和Extension之间是独立的二进制包, 不可以互访对方的沙盒, extension是containing app的插件.
- 为了实现containing app和extension之间共享数据, ios 8引入了App Group, 让同一group下的所有app共享数据.
- extension app ID 于containing app的命名是有规则的.
- extension app id以containing app id为前缀.
- 公用证书, 公用证书key pair中的private key进行codeSign
证书、签名:
- code signing identity必须与provisioning profile匹配
- code signing identity中配置的certificate必须在本机keychain access中存在对应的public/private key pair, 否则编译会报错.
- 上面的合法性验证是WWDRCA.cer完成的.
- 证书其实就是公钥, 私钥被用来进行数字签名[数字签名就是用哈希算法生成digest]
真机启动:
- App在Mac/ios设备上启动时, 会将xcode对其进行的配置与provisioning file(pp)进行匹配校验, 就是看bundle ID是否与app ID匹配, codesign得到的结果是否在pp中, 设备ID是否在pp文件里.
- ios/mac设备使用codesign所使用的开发证书(dongzhao)来判断App的合法性: 使用证书公钥解出App的signature以确定App是否来源可信; 再计算下app 二进制的哈希结果以确定App没有被篡改过, 内容完整.
- 基于Provisioning Profile校验了CodeSign的一致性;
- 基于Certificate校验App的可靠性和完整性;
- 启动时,真机的device ID(UUID)必须在Provisioning Profile的ProvisionedDevices授权之列。
多台机器共享开发账户/证书(p12):
- 在Keychain Access中选中欲导出的certificate或其下private key, 导出p12文件(holds the private key and certificate).
- 其他Mac机器上双击Certificates.p12即可安装该共享证书. 有了共享证书之后, 在开发者网站上将欲调试的iOS设备注册到该开发者账号名下, 并下载对应证书授权了iOS调试设备的pp文件, 便可在iOS真机设备上开发调试.
Reference
2. 属性和实例变量
写法一:
@interface MyViewController :UIViewController
@property (nonatomic, retain) UIButton *myButton;
@end
-
- self.myButton调用的是myButton属性的getter/setter方法
-
- 实例变量可以理解成C++的成员变量
-
- object-c 2.0中@property会自动创建_开头的实例变量
写法二:
#import "ViewController.h"
@interface ViewController ()
@property (nonatomic, strong) UIButton *myButton;
@end
@implementation ViewController
@synthesize myButton;
归纳总结:
@synthesize只能出现在@implementation代码段中- 让编译器自动生成setter和getter
@synthesize myButton = xxx这种写法指定了与属性对应的实例变量,那么self.myButton其实操作的是实例变量_xxx, 而不是myButton了;@syncthesize myButton生成的实例变量是myButton,也可理解成操作的是myButton, 如果没有@syncthesize myButton, 生成的实例变量就是_myButton
这四条总结起来就是@synthesize映射了属性与实例变量,self.某某调用的是实例变量的setter和getter;默认的映射是与之同名的实例变量(可见有了这个关键字生成的是与之同名的实例变量);没有这个关键字就默认生成_某某的实例变量。简记为”做映射, 操作实例, 默认同名”
属性和实例变量的关系:
- 属性对成员变量扩充了存取方法;
- 属性默认会生成带下划线的成员变量;
- 但只声明了变量,是不会有属性的
属性中的参数: @property(nullable, nonatomic, copy)、@property (class, readonly, strong)
3. extern、static、const
简单总结:
- extern-全局变量修饰,跨文件访问
- const-修饰右边变量
- static-定义开始到文件结尾(修饰全局变量)
- static-定义开始到函数结束或语句块结束(修饰局部变量)
- static-本文件使用(修饰函数)
const static应用场景:本文件中经常使用的字符串常量。
eg1.:
classA.h文件:
@interface ClassA : NSObject
+ (nullable NSUserDefaults *)sharedUserDefaults;
@end
extern NSString * _Nonnull WWKEPostBoxIdentifierHost;
extern NSString * _Nonnull WWKEPostBoxIdentifierShareExtension;
classA.m文件:
#import "ClassA.h"
NSString *APPGROUP_NAME = @"group.com.tencent.ww";
NSString *WWKEPostBoxIdentifierHost = @"host";
NSString *WWKEPostBoxIdentifierShareExtension = @"shareext";
@implementation ClassA
+ (nullable NSUserDefaults *)sharedUserDefaults{
return [[NSUserDefaults alloc] initWithSuiteName:APPGROUP_NAME];
}
@end
classB.h文件:
#import "ClassA.h"
@interface ClassB : ClassA
@end
extern NSString * _Nonnull WWKEPostBoxIdentifierShareExtension1;
classB.m文件:
NSString * WWKEPostBoxIdentifierShareExtension1 = [WWKEPostBoxIdentifierShareExtension copy];
@implementation ClassB
+ (nullable NSUserDefaults *)sharedUserDefaults{
WWKEPostBoxIdentifierShareExtension1 = [WWKEPostBoxIdentifierShareExtension copy];
return [[NSUserDefaults alloc] initWithSuiteName:@"sss"];
}
@end
NSString * WWKEPostBoxIdentifierShareExtension1 = [WWKEPostBoxIdentifierShareExtension copy];这行有bug:
nitializer element is not a compile-time constant
想得通, WWKEPostBoxIdentifierShareExtension初始化的时机不能保证在这行之前完成,因此有这个bug。注意,WWKEPostBoxIdentifierShareExtension1 = [WWKEPostBoxIdentifierShareExtension copy];这行是没问题的,这说明此时WWKEPostBoxIdentifierShareExtension已经初始化完毕。
eg2:
classA.h和classA.m文件不变,classB.h变成:
#import "ClassA.h"
@interface ClassB : ClassA
@end
classB.m变成:
#import "ClassB.h"
NSString *WWKEPostBoxIdentifierHost = @"host";
NSString *WWKEPostBoxIdentifierShareExtension = @"shareext";
@implementation ClassB
@end
此时会报链接错误, 注意,extern修饰的变量不要出现两次初始化。经调试,只要把任意一处的初始化删掉一个都可通过编译。
Reference
4. grammar1
- NSUserDefaults: 通过
NSUserDefaults访问plist文件中的偏好设置 - 写在
.h和.m中的@property有什么区别: 初步看是作用域的问题,后续仔细看下@property学习下property - NSFileCoordinator是协调在host app与extension apps之间移动数据的非UI组件
- CFNotificationCenterGetDarwinNotifyCenter: 1. 系统级的通知中心, 可用于Extension和容器app的交互, 2. NSNotificationCenter,KVO,Delegate都不行,因为Extension和容器app不是一个App. 此外,如果想实现更复杂的进程间的交互,可以使用
MMWormhole - Category和Extension: 一种对类进行扩展的方法, 无需创建子类就可以添加新方法, 可以为任何已经存在的class添加方法, 包括没有源码的类.
Reference
@class说明
- @class只是告诉编译器,其后面声明的名称是类的名称,至于这些类是如何定义的,暂时不用考虑,后面会再告诉你。
- 编译效率和循环引用的问题。
NSTimeInterval _start = [[NSDate date] timeIntervalSinceReferenceDate];
- 时间相关语法
nonatomic
- 在ios中,一般都声明为非原子的,这处于性能的考虑
- 在mac OS X中,可以声明为atomic, 因为在mac上不需要怎么考虑性能问题
- 即使是atomic也不一定能保证是线程安全的,还需要更深层次的锁定机制才行[]
strong与weak
- ARC是编译器特性而不是运行时特性, 因此不是类似于其他语言的垃圾回收器,其性能与手动内存管理是一样的
- Strong指针的特点就是可以保持对象的生命,也就是说:当指针获得新值或者不存在时(如局部变量方法返回、实例变量对象释放)对象可能被释放。之所以这里说的是”可能”,理由在于:一个对象可以有多个”拥有者”
- 默认所有实例变量和局部变量都是Strong指针
- weak型的指针变量仍然可以指向一个对象,但是不属于对象的拥有者. 也就是说只有使用权, 而不会影响对象的回收。
- weak型的指针变量自动变为nil是非常方便的,这样阻止了weak指针继续指向已释放对象,避免了野指针的产生,不然会导致非常难于寻找的Bug,空指针消除了类似的问题(野指针跟阳痿差不多)
- weak指针主要用于“父-子”关系
- 有了ARC之后,只需要关心对象之间的关联,也就是”谁是谁的拥有者”
Reference
5. OC与C++混编
主要总结C++调用OC的三种情况:
- 在C++的头文件中写个struct把oc对象藏起来
- 在C++的头文件中这样
id xxx - 通过c的函数指针把C++和OC结合起来
- OC对象里函数指针包起实际调用的方法
- 把OC本身通过void*传给C++对象(与调用无关,只是传递)
- 把OC的函数指针传给C++对象
详细介绍见参考文章
Reference
6. ios的黑魔盒
class_getInstanceMethod(Class _Nullable cls, SEL _Nonnull name)该函数会根据sel返回objc_method结构体指针,只要sel对应的IMP不发生改变,这个结构体指针就不会变,验证如下:
验证一:
Method originMethod = class_getInstanceMethod([self class], orginSel);
Method originMethod1 = class_getInstanceMethod([self class], orginSel);
NSLog(@"originMethod: %p", originMethod);
NSLog(@"originMethod1: %p", originMethod);
if (class_addMethod([self class], orginSel, method_getImplementation(overrideMethod) , method_getTypeEncoding(originMethod)))
{
originMethod = class_getInstanceMethod([self class], orginSel);
NSLog(@"originMethod: %p", originMethod);
}
输出:
2018-06-20 22:12:23.357897+0800 HookDemo[7962:540915] originMethod: 0x1acfcacb0
2018-06-20 22:12:23.358423+0800 HookDemo[7962:540915] originMethod1: 0x1acfcacb0
2018-06-20 22:12:23.358687+0800 HookDemo[7962:540915] originMethod: 0x10099ee28
验证二:
Method originMethod = class_getInstanceMethod([self class], orginSel);
Method originMethod1 = class_getInstanceMethod([self class], orginSel);
NSLog(@"originMethod: %p", originMethod);
NSLog(@"originMethod1: %p", originMethod);
class_replaceMethod([self class], orginSel, method_getImplementation(overrideMethod), method_getTypeEncoding(overrideMethod));
originMethod = class_getInstanceMethod([self class], orginSel);
NSLog(@"originMethod: %p", originMethod);
输出:
2018-06-20 22:20:29.814846+0800 HookDemo[8004:543573] originMethod: 0x1acfcacb0
2018-06-20 22:20:29.815427+0800 HookDemo[8004:543573] originMethod1: 0x1acfcacb0
2018-06-20 22:20:29.815481+0800 HookDemo[8004:543573] originMethod: 0x135d76068
通过这两个验证实验可知,只要IMP发生变化,就会返回不同的objc_method结构体指针。接下来我要从IMP角度来验证加深对class_getInstanceMethod的理解,代码如下:
IMP impl1 = method_getImplementation(originMethod);
IMP impl2 = nil;
IMP impl3 = nil;
if (class_addMethod([self class], orginSel, method_getImplementation(overrideMethod) , method_getTypeEncoding(originMethod)))
{
impl2 = method_getImplementation(originMethod);
originMethod = class_getInstanceMethod([self class], orginSel);
impl3 = method_getImplementation(originMethod);
}
NSLog(@"impl1 %@ impl2", (impl1 == impl2) ? @"==" : @"!=");
NSLog(@"impl2 %@ impl3", (impl2 == impl3) ? @"==" : @"!=");
输出:
2018-06-20 22:34:33.720940+0800 HookDemo[8068:548091] originMethod: 0x1acfcacb0
2018-06-20 22:34:33.721653+0800 HookDemo[8068:548091] impl1 == impl2
2018-06-20 22:34:33.721701+0800 HookDemo[8068:548091] impl2 != impl3
输出结果间接验证了:只要IMP发生变化,就会返回不同的objc_method结构体指针originMethod,这里可以将class_getInstanceMethod的实现原理理解为:
- 根据
SEL和IMP来创建objc_method对象,并返回地址,如:originMethod
另外有一点要注意:
- 执行
class_addMethod或者class_replaceMethod这种可以改变IMP的函数后并不会直接改变originMethod所指向的对象(从impl1 == impl2可以看出)
7. viewDidLoad, viewDidAppear执行顺序
- viewDidLoad:视图 load进入内存后调用(loadView[创建view]后执行)
- viewDidAppear: view显示在屏幕后被调用
8. Singleton与多线程
singleton的三个基本要素:
- 静态成员pInstance
- 静态函数Instance
- private或protected(可用于继承的场景)构造函数
二元锁/互斥量: 被锁住的代码块是一个执行单元, 只有完整的执行完了, 别的线程才能执行, 所以不存在两个线程同时进入这个代码块.
多线程singleton:
- 构造函数私有、静态函数访问唯一的实例(普通单例不是线程安全, 多线程下存在多次判断为NULL进而多次new对象的情况)
- 将分配资源的地方即new对象加锁, 以达到线程安全.(这样加锁, 每一次进入静态函数的时候都会加锁, 我们希望的是: 仅第一次产生实例时才加锁, 非NULL时直接return)
9. NSData
NSData是用来包装数据的, NSData存储的是二进制数据, 屏蔽了数据之间的差异, 文本、音频、图像等数据都可用NSData来存储.
10. iOS 文件目录
iphone沙盒模型的四个文件夹分别是documents,tmp,app,Library. 沙盒目录即home目录.
11. Runloop
Reference
12. ios消息机制
PC工程配置相关知识(20180710)
一些名词:
- vs项目本身是基于MSBuild的
- 解决方案: 多个工程的集合, 使多个项目之间方便的共享文件和代码库. 大型项目的做法: 代码集中在一个路径下, 然后其他工程包含这个路径.
- VC++目录中的可执行文件目录: 项目如果需要使用哪些可执行文件就在这设置, 在创建C++工程时, 会对PATH环境变量中的值进行继承. 注意这里说的是可执行文件而不是DLL.
- 输出目录: 指出exe在哪
- 中间目录: 指出*obj二进制文件在哪
- $(OutDir)$: 在”输出目录”看
- 工作目录: 进行某项操作的目的目录, 程序运行后唯一识别的默认目录, 即工作后只认识这个目录. 比如你的程序运行的过程中产生一个图片, 如果不指定路径, 那么就生成在工作目录下
- 程序运行过程中动态加载的dll就可以放在工作目录中
- 工作目录在代码中用GetCurrentDirectory之类的函数获取
- 当启动调试后, 自动把工作目录设置为vs项目属性中的工作目录(可见, 这里的属性设置是给调试用的)
- 如果不使用vs的调试启动exe,而是直接双击exe文件启动一个新进程时,会自动把这个新进程的工作目录设置为exe文件所在的目录
- 如果发布的时候不把工作目录(指的是vs的设置)内的东西拷到exe所在的目录内,就会运行出错(可通过后期生成事件拷贝过去), 因为此时工作目录不再是vs中设置的了, 而是exe文件所在的目录.
- vs中默认的vc++工程的工作目录是vs工程所在目录即.vcproj文件所在目录
- $(TargetPath): 目标输出文件的全路径名, 一般情况下等于”输出文件”属性所代表的值
- 如果项目名称为ss,则TargetName系统变量的值就是ss,TargetExt是扩展名为exe
- 调试栏目下的所有选项都是为了调试服务的,如果不用调试按钮,这些选项就不起作用
- 链接器->常规->输出文件(表示链接器生成的exe文件放在哪以及生成的exe文件名称)
由于windows平台的动态库隐式链接需要.h和.lib(dll的描述信息), 因此, 想在windows上对动态库进行隐式链接就需要做三个配置: 1. 在包含目录中指定头文件的路径, 2. 在库目录中指定.lib信息, 在附加依赖项中指定你所需要的xx.lib描述文件.
Reference
-[1] VS项目属性的一些配置项的总结(important)
IPC(20180806)
Tue Jun 5 21:28:29 CST 2018
Notes of Multi-process Architecture. 浏览器的每个tag都是一个独立的进程, 而主进程(browser process或Browser)则管理着这些tab进程(render processes或Renderers)和插件进程. 这些Renderer使用Blink(开源渲染引擎)来解析、布局HTML。主进程和render进程以及他们之间的关系如图所示:
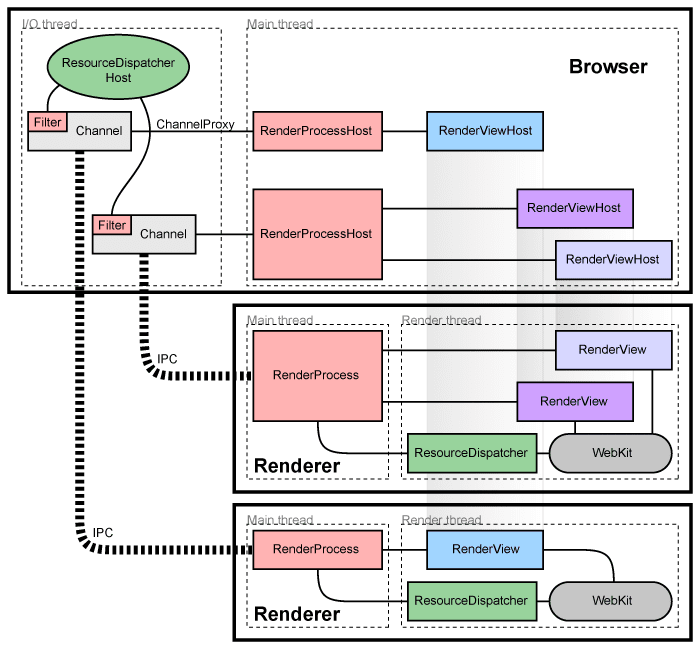
图中的关键词解释(与进程相关的部分):
- RenderProcess: 是 Renderer 中的一个全局对象, 管理着和主进程 Browser 之间的通信同时维持着全局状态.
- RenderProcessHost: 这是 Browser 中的一个与 RenderProcess 对应的全局对象, 其作用为: a. 管理着主进程 Browser 的状态, b. 与 RenderProcess 通信.
Browser 和 Renderer 之间的进程通信(IPC)通过Chromium’s IPC system实现.
图中的关键词解释(与View相关的部分):
- RenderView: 该对象是与标签 tab 相关的,在每个 Renderer (进程)中有一个或者多个 RenderView 对象,被 RenderProcess (前文关键词解释中提到的对象)管理。
- RenderViewHost: 该对象与 Renderer 中的每个 RenderView 对应,相应的受 RenderProcessHost 管理.
每个 RenderView 都有一个view ID, 在同一个 Renderer 中是唯一确定的, 但是在 Browser 中却不一定唯一, 因此要确定一个view, 则需要一个 RenderProcessHost 和一个view ID. Browser 和view通信需要通过 RenderProcessHost , 可表示为:
- RenderProcessHost –(IPC)-> RenderProcess —> RenderView
在Renderer中:
- RenderView 通过 RenderProcess 和与之相应的 RenderViewHost 交互, 同时与 WebKit 嵌入层交互, 每个 RenderView 代表着一个web页面的内容.
在Browser中:
- Browser 中有若干个 RenderProcessHost 与__Renderer__对应.
- RenderViewHost 与 RenderView 交互, 类似的 RenderWidgetHost 与 __RenderWidget__交互.
Sharing the render process
通常, 每打开一个tab或者一个window, Browser都会创建一个进程Renderer, 然后Renderer创建一个与这个tab/window相应的RenderView对象. 有时候,我们希望在tab之间共享 Render, 也就是这样一种应用场景: “打开一个tab后, 这个tab共享某一个 Renderer”, 亦或是: “当 Renderer 的个数太多时, 我们把新打开的tab指向某已存在的 Renderer “. 详细的 Renderer 重用策略可参看:Process Models.
Sandboxing the Renderer
沙盒机制, 简单来说就是限制 Renderer 对系统资源如: network、filesystem的访问.
Giving back memory
应用场景主要是: low-memory situations . 在这种应用场景下处理 Renderer 内存的一些策略.
Plug-ins and Extension.
类似于Firefox的NPAPI的插件运行与自己的进程, 而不是在 Renderer . 详细内容可查阅: Plugin Architecture.
Chromium-IPC(Wed Jun 6 15:17:49 CST 2018)
Chromium利用异步管道(asynchronous pipe)来实现IPC, asynchronous的方式确保了两端不等待对端。
IPC in the browser
在Browser中, 和Renderer的通信是通过一个单独的I/O线程完成的. 主线程发送到Renderer中的view的消息是通过ChannelProxy发出的, 同样的从view发出的消息也要通过代理ChannelProxy发送到主线程, 这种由单独的一个I/O线程来捕获消息的方式主要是为了防止阻塞UI. Brower中的主线程通过RenderProcessHost在Channel中插入ChannelProxy:MessageFilter, 这个filter运行在I/O线程中可以拦截资源请求消息, 然后将其转发到ResourceDispatcherHost.
IPC in the renderer
每个Renderer也有一个专门负责通信的线程(主线程), 然后渲染和其他处理操作在另外一个线程. 从Browser发到Webkit的消息要经由Renderer中的主线程, 反之亦然.
Messages
两个主要的消息类型: routed、control.
- routed: 请求view渲染一块区域
- control: 请求资源或修改剪贴板(与view无关的)
简介几种消息:
- View message : 发送给RenderView的消息(Browser —> Renderer)
- ViewHost message : 发送给RenderViewHost的消息(Renderer —> Browser)
- Frame message : 发送给RenderFrame的消息(Browser —> Renderer)
- FrameHost message : 发送给RenderFrameHost的消息(Renderer —> Browser)
- PluginProcess message : 发送给PluginProcess的消息(Browser —> plugin process)
- PluginProcessHost message : 发送给PluginProcessHost的消息(plugin process —> Browser)
消息声明、消息发送、消息捕获:
1. 声明
- 从Renderer到Browserer的routed消息: IPC_MESSAGE_ROUTED2(FrameHostMsg_MyMessage, GURL, int)
- 从Browser到Renderer的control消息: IPC_MESSAGE_CONTROL0(FrameMsg_MyMessage)d
- 注意:
ipc_message_utils.h,navigation_params.hframe_messages.h这是与消息序列化相关的文件.
2. 发送
通过channel发送消息, 比如在RenderProcessHost中就包含channel, 这个channel可以把来自于Browser中的UI线程的消息发送给Renderer. 在RenderWidgetHost(为RenderViewHost的基类)中有更为方便的消息发送方式: 即通过Send函数. eg:
- Send(new ViewMsg_StopFinding(routing_id_));
- 这里之所以要routing id, 是因为只有这样才可以找到正确的View/ViewHost, 然而我的应用没这个需求.
3. 捕获
- 通过实现IPC::Listener接口来捕获消息, 其中最重要的函数就是
OnMessageReceived
Channels
IPC:Channel定义了基于pipe的交互方法:
- IPC:SyncChannel: 同步等待对某些消息的相应(Browser不会用这个方法, Renderer会在”Synchronous messages”用到该方法)
synchronous messages
站在Renderer的角度, 有些消息是要同步的. 比如webkit中的拼写检查和js的cookies, 这些应用的特点是:” 发出一个请求后是需要应答的”. eg:
- webkit发出一个同步类型的IPC请求后, 该请求通过IPC:SyncChannel分发到Renderer中的主线程中的SyncChannel, (这个步骤发送异步消息也是如此), SyncChannel接到这个消息后会阻塞webkit直至SyncChannel接受到一个应答消息后再解除对webkit线程的阻塞. 在webkit阻塞过程中(也就是等待同步消息应答), renderer中的主线程会收到webkit需要处理的消息, 这个时候就需要把这些消息放到webkit的消息队列理, 在webkit线程unlock之后再以此处理这些消息, 可见同步消息的处理是无序的(out-of-order). 同步消息和异步消息使用同样的
IPC_MESSAGE_HANDLER
小结
初步把Chromium的IPC理了一遍, 接下来回到Chromium官方文档的开始部分继续整理.
$\alpha$-Blending(20180829)
可以利用$\alpha$通道融合原理在拿不到图片的情况下实现傅立叶变换的线性性质. $\alpha$通道决定了透明度, 称之为$\alpha$ mask. 理论部分很简单, 即: $I = \alpha F +(1 - \alpha) B$.
练习list(20181101)
- 1. GCDAsyncSocket、2. Web_rtc、3. 多线程、4. TCP、心跳、5. MRC与ARC、6. 堆对象、栈对象、7. GCD、8. The Chromium Projects、9. The Boost-library
1. GCDAsyncSocket
- source code dir=
/Users/linmengran/work/ios/xuyaohui/CocoaAsyncSocketTip-master/CocoaSyncSocket/Pods/Pods.xcodeproj - 黏包、断包处理实例=
/Users/linmengran/work/ios/xuyaohui/IM_PacketHandle-master - testReplayKit2/GCDAsyncSocketManager-master—我的ipc层主要参考了这个, 这是对AsyncSocket proj的一个封装
抓包:
- 先关联设备: rvictl -s uuid
- 再启动wireshark: sudo su、wireshark &
- 显示设备: rvictl -l
- 关闭设备: rvictl -x uuid
- 退出超级管理员: exit
直接关掉wireshark重来会出问题,所以我就用了下面的命令来管理wireshark
- 查看进程(linux):
ps -ef | grep wireshark
linmengran$: ps -ef | grep wireshark
0 37696 13351 0 9:38下午 ttys004 0:00.02 sudo wireshark
0 37702 37696 0 9:38下午 ttys004 0:08.11 /Applications/Wireshark.app/Contents/Resources/bin/wireshark-bin
501 39068 13351 0 9:41下午 ttys004 0:00.00 grep wireshark
+kill掉这些进程: sudo kill -9 37696 37702 39068
2. Web_rtc
P2P连接的特点: 数据通道一旦形成, 中间是不经过服务端的, 数据直接从一个客户端流向另一个客户端. 注意: WebRTC虽然提供了P2P的通信, 但并不意味着WebRTC不需要服务器. 至少有两件事必须要要用到服务器:
- 浏览器之间交换建立通信的元数据(信令)必须要通过服务器。
- 为了穿越NAT和防火墙。
NAT:
- 关于这部分内容先说下结论吧:”主动发包的一方被知晓(包括IP/Port,发送方的NAT), 主动方可收包(突破主动方的NAT)”
WebRTC就是根据这一结论, 突破的NAT限制, 做法是:
- 两端同时向一个公网服务器发包,然后公网向这两端发对端的IP/port, 这样这两端就突破了NAT限制
task:
- IOS下WebRTC环境搭建:
- NAT实现
- ICE协议框架
- WebRTC protocols
- google “wireshark抓VoIP”
Reference
3. 多线程
在项目/Users/linmengran/work/ios/code_backup/delegate_test/delegate_test.xcodeproj 练习。我把NSoperation之前的撸完了。
Reference
4. TCP、心跳
心跳:客户端每隔一段时间向服务端发送自定义指令,以判断双方是否存活。(undone)
-
- google: “TCP的KeepAlive无法替代应用层的心跳保活机制–连接活着但业务已死”
5. MRC与ARC
-
- 引用计数器操作
Reference
6. 堆对象、栈对象
- 代码区-就是可执行文件的内存镜像,白话来说就是把二进制码怼到内存里
- 数据区、BSS区-两者的区别就是初始化和未初始化, 我的疑问就是:既然都是全局变量和静态变量为什么还要单独区分?是为了检索效率
- 常量区-和代码区、数据区的区别就是:常和变的区别。注意:static标识的放在数据区
- 堆-动态分配的
- 栈-局部变量、函数参数。注意:函数被调用时再把参数压入调用的进程栈中,白话来说就是谁调用了谁就再压一遍。
-
- 为什么用栈,因为方便恢复现场。那么为什么栈容易恢复现场?(undone)
Reference
7. GCD
Reference
-1. GCD[undone]
8. The Chromium Projects
- 成功编译ios工程
Reference
- 1. chromium
- 2. Checking out and building Chromium for iOS
- 3. High-level architecture Chromium
- 4. Chromium基础库说明
9. The Boost-library
undoneReference
工作中涉及到的操作
1. 调试
2. git
- 查看远程分支: git branch -r
- 提交文件夹下的更新: git add -u xxx/yyy
commands:
- git log: review exixting commits
- git log -p
- git log –stat
- git log -p -w
- git log sha
- git log –oneline
- git log -p sha
- git show : show the recent changes
- git show sha
- git diff: Display the difference between two versions of a file, This tool will tell us what changes we’ve made to files before the files have been committed
- git tag: add tags to specific commits
- git branch: Allow multiple lines of development, Let you develop different features of your project in parallel without getting confused as to which commits belong to which feature
- git checkout: You will be able to switch between different branches and tags#### 3. c++11支持
- git merge: Combine changes on different branches [Take change on different branches and combine them together automatically.]
- git tag -a v1.0: create an annotated flag, and tag the most recent commit.
- git tag v1.0: create an lightweight tag
- git tag -a v1.0 a87984:
verify tag:
- -git tag
- -git log –decorate
delete tag:
- -git tag -d v1.0
- -git tag –delete v1.0
切分支:
- git checkout -b feature_xxx_demo remotes/origin/feature_xxx_demo
- git show 981734907213409712309847
git代理
- git config –global http.proxy http://dev-proxy.oa.com:8080
~/.gitconfig中配置代理
[http] proxy = xxx [https] proxy = xxx
配置user name和email
lmr@lmr-ThinkPad-T470-W10DG: git config --global user.name "lmrshare"
lmr@lmr-ThinkPad-T470-W10DG: git config –global user.email "cqulinmengran@gmail.com"
拉分支
//这样push不用输很长一串,直接push就行了
git checkout -b release_x_x_xx_x remotes/origin/release_x_x_xx_x
发布分支
git pull
git co -b release_x_x_xx_x remotes/origin/release_x_x_xx_x
查看git远程库信息
git remote -v
查看remote地址,远程分支,还有本地分支与之相对应关系等一系列信息
git remote show origin
一个比较常用的是,在解决合并冲突时使用哪种差异分析工具。比如要改用 vimdiff 的话
git config --global merge.tool vimdiff
关于工具组合的一个经验(sourceTree + xcode + 命令行):
- sourceTree: 看日志,文件暂存
- xcode: 本地提交代码
- 命令行:pull rebase , push , 冲突解决
常用命令补充
mengranlin@imac:~$ git fetch origin-------下载远程仓库的所有变动
mengranlin@imac:~$ git checkout -b xxx_xxx------新建并切换到xxx_xxx分支
mengranlin@imac:~$ git checkout xxx_xxx------切换到xxx_xxx分支
mengranlin@imac:~$ git branch testing-------新建一个testing分支[在当前commit对象上新建一个分支指针]
mengranlin@imac:~$ git branch-------列出本地分支
mengranlin@imac:~$ git remote-------列出远程仓库
mengranlin@imac:~$ git remote -v-------列出、显示对应的地址
mengranlin@imac:~$ git fetch-------只是将远端的数据拉到本地仓库,并不自动合并到当前工作分支
注意事项:
- commit前diff一下,确定代码有没有冲突
- 如果commit之前没diff, 我一般会在push之后git log,然后git show
配置GitHub
- 生成本地SSH key(用于远程仓库跟本地连接)
lmr@lmr-ThinkPad-T470-W10DG: cd ~/.ssh lmr@lmr-ThinkPad-T470-W10DG: ssh-keygen -t rsa -C "cqulinmengran@gmail.com" - 这样会生成
id_rsa和id_rsa.pub这两个文件, 接着增加SSH Key到GitHub中, 也就是将id_rsa.pub中的内容copy一份到Github中。到现在为止,把Git、Github配置完了. 接下来就可以托管项目了
管理项目
- 进入本地项目路径
work-notes-2018, 然后做如下操作lmr@lmr-ThinkPad-T470-W10DG: git init lmr@lmr-ThinkPad-T470-W10DG: git status lmr@lmr-ThinkPad-T470-W10DG: git remote add origin https://github.com/lmrshare/work-notes-2018.git (对远程仓库进行管理) lmr@lmr-ThinkPad-T470-W10DG: git pull https://github.com/lmrshare/work-notes-2018.git (新建仓库的时候相当于做了一次提交, 所以要pull一次) lmr@lmr-ThinkPad-T470-W10DG: git status lmr@lmr-ThinkPad-T470-W10DG: git add . lmr@lmr-ThinkPad-T470-W10DG: git commit -m 'lubuntu first commit' lmr@lmr-ThinkPad-T470-W10DG: git push lmr@lmr-ThinkPad-T470-W10DG: git status
可能需要的命令
- 可能需要新建分支, 如果上面的操作不行,就试试下面的操作:
lmr@lmr-ThinkPad-T470-W10DG: git checkout --orphan gh-pages
3. c++11支持
- 要支持c++11,需要在CMakeLists.txt中加上这句: add_definitions(-std=c++11)
Experience about constructing codeblocks project:
mac$: cmake .. -G "CodeBlocks - Unix Makefiles"
There should be the contents in the CMakeLists.txt file
set(CMAKE_BUILD_TYPE "Debug")
set(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -Wall -g -ggdb")
set(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3 -Wall")
project->Properties->Build targest
4. nm静态库
nm /Users/linmengran/work/git/ios/xxx/ssss | grep Masonrygrep "\-\->ycyc" tmp.txtgrep "sent" ~/Documents/console.log | head -5k
5. shell
shell代理
export http_proxy=xxx
export https_proxy=xxx
linux主要发行版
- redhat系列和debian系列,主要区别就是软件安装, 其他的基本一致
redhat主要分:
- fedora(自己玩一玩)和RHEL(稳定版)两个主要系列, 这两个系列都收服务费; 而CentOS是社区维护版本,是RHEL系列,它是完全免费的, 很多公司都用CentOS作为服务器版本
- SuSE欧洲用得多, gentoo linux对使用者的要求比较高
debian主要分:
- ubuntu(桌面漂亮)和KNOPPIX(不用安装)
开源软件:
- 商业软件: 典型特征是收费, 不开放源代码.
- 开源软件: 阿帕奇, NGINX, python, Ruby, mongoDB, MySQL
特点:
- 免费
- 开放源代码, 所以安全
- 散布和改良的自由
设备分区文件名:
- 现在无论服务器还是个人电脑, 硬盘都主要是SATA, 因此你现在看到最多的是/dev/sda1, /dev/sda2, 很少有/dev/hd1(IDE硬盘)
- 1, 2, 3, 4只能是主分区或扩展分区, 因此编号5一定是第一个逻辑分区
挂载
- 给分区指定挂载点.
- 挂载点必须是目录, 而且是空目录
- 只要有了根分区/和交换分区swap, linux就可以正常使用
- swap 分区: 内存两倍, 但最大不超过2G
- /boot: 这个可以没有, 写入启动数据, 不用太大, 200MB即可, 好处就是: 有了这个分区m 即使根分区写满, 也能正常启动linux.
Keras相关的经验
Exp1:
plot_model(model, to_file='model.png',show_shapes=True)----这行代码可以将model保存成图片。
model.summary(): 打印出模型的概况
Exp2:
1. isinstance---isinstance(object,type-or-tuple-or-class) -> bool
2. python 创建类、继承、抽象方法
class xx(object):
@abstractmethod
def xxx(self, xx1,xx2):
3. python的threading
Exp3:
1. dataset_dict = {'smart':Smartiterator, 'discovery':DicoveryIterator}
2. dataset_dict['smart'](dir,args)
Exp4:
1. from utils.eval_utils import get_metrics --- 从utils文件夹下的eval_utils.py文件导入get_metrics函数
Exp5:
metric = (lambda f, t : lambda gt, pred : f(gt, pred, t))(metric_func, thresh)
Exp6:
我对这句的理解: lambda f, t : lambda gt, pred : f(gt, pred, t) 是函数部分, (metric_func, thresh) 是参数部分。起初,我认为可以等价为:
metric = lambda gt, pred : metric_func(gt, pred, thresh)
经测验这是错误的, 原因在于:这里的metric_func不再是具体的函数,没有意义。举例说明:
>>> func3 = lambda x, y, z : x + y + z
>>> F = lambda gt, pred : func3(gt, pred, 2)
>>> F(1,2)
出错: ***NameError name 'func3' is not defined
如果把func3当成参数传递就没问题:
>>> F = (lambda f : lambda gt, pred : f(gt, pred, 2))(func3)
>>> F(1,2)
5
简记:看到lambda, 配对,带入。
python 中lambda的用法:
eg1:
>>> func = lambda a, b : a+b
>>> func(1,3)
>>> 4
eg2:
def func(n)
return lambda x, n : x + n
>>> f = func(3)
>>> f(2)
>>> 5
eg3(作为一个小函数传递:):
>>> pairs = [(4, 'four'), (3, 'three'), (2, 'two'), (1, 'one')]
>>> pairs
[(4, 'four'), (3, 'three'), (2, 'two'), (1, 'one')]
>>> pairs.sort(key = lambda pair : pair[0])
>>> pairs
[(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four')]
返回类型:
>>> type(xx)
Tensorflow
tensorflow中文文档中的MNIST中有几个话题可以看一下: Softmax, cross-entropy, backpropagation algorithm, 其他许多优化算法
为什么tensorflow采用图的方式
- 避免切换开销: 如果使用函数库来进行高效的数值运算, 比如Nunpy, 会把类似矩阵乘法这样的计算用外部语言来实现, 然后再转换成python, 从外部语言转换python的每一个步骤都有很大的开销, 因此为了避免这样的开销, tensorflow不单独地运行单一的复杂计算, 而是让我们可以先用图描述一系列可交互的计算操作, 然后全部一起在Python之外运行, 这与Theano或Torch的做法类似.
- 后台机理: tensorflow在后台给你的计算图添加一系列计算操作单元用于实现反向传播和梯度下降, 然后返回给你一个操作(单一操作), 运行这个操作就会用梯度下降来训练你的模型, 微调你的变量
MNIST机器学习入门
- 这个demo比较好, 看完后会对tensorflow有个基本的了解
- placeholder与Variable, 前者是占位符, 比如可用于input; 后者表示一个可修改的变量, 比如可用于定义权重或者bias
- tf.argmax(y,1): 最大值1所在的索引位置
- cross-entropy比较粗糙的理解是, 交叉熵是用来衡量我们的预测用于描述真相的低效性.
- correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)): 这行代码会给我们一组布尔值, 为了确定正确预测项的比例, 我们可以把布尔值转换成浮点数, 然后取平均值. 例如, [True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
深入MNIST
- 这篇文章与前一篇的主要区别在于, 后者通过使用cnn将正确率提高到了99%
- tensorflow依赖于一个高效的c++后端, 于后端的这个连接叫做session
- tensorflow程序流程: 建立图, session中启动这个图
- InteractiveSession: 你可以更加灵活地构建你的代码, 它能让你在运行图的时候, 插入一些计算图, 这对于工作在交互式环境中的人们来说非常便利
- Variable: 变量需要通过seesion初始化后, 才能在session中使用
- 为了减少过拟合, 我们在输出层之前加入dropout: 训练启用, 测试关闭
基本使用
- 使用graph来表示计算任务, session中执行graph, tensorflow表示数据, variable维护状态, feed和fetch可以为任意操作赋值或从中获取数据
- sess.run()执行图中的op
- 一个tensor包含一个静态类型rank, 和一个shape
- fetch, 在执行run方法时传入一些tensor, 这些tensor可以取回结果
- feed使用一个tensor值临时替换一个操作的输出结果, eg: placeholder中的应用
教程
- 这部分提供了几个应用的demo, 包括: MNIST, CNN, 单词的向量表示, RNN, Sequence-to-Sequence model等等
运作方式
- 这部分以教程的形式介绍了tensorflow的变量, 可视化, 线程队列, 添加新的op, 自定义数据的readers, 使用GPUs, 共享变量
- 保存变量: 用tf.train.Saver()创建一个Saver来管理模型中的所有变量
saver = ft.train.Saver()
saver.save(sess, "/tmp/model.ckpt")
- 恢复变量: 用同一个Saver对象来恢复变量, 注意, 当你从文件中恢复变量时, 不需要事先对它们做初始化
saver = tr.train.Saver()
saver.restore(sess, "/tmp/model.ckpt")
- 选择性的存储与恢复: 有时候仅保存和恢复模型的一部分变量很有用, 你也许训练得到了一个5层神经网络, 现在想训练一个6层的新模型, 可以将之前5层模型的参数导入到新模型的前5层中.
- 可以通过给tf.train.Saver()构造函数传入Python字典, 很容易地定义需要保持的变量及对应名称: 键对应使用的名称, 值对应被管理的变量
- 如果需要保存和恢复模型变量的不同子集, 可以创建任意多个saver对象, 同一个变量可被列入多个saver对象中, 只有当saver的restore()函数被运行时, 它的值才会发生改变.
- 如果你仅在session开始时恢复模型变量的一个子集, 你需要对剩下的变量执行初始化op.
# Create some variables.
v1 = tf.Variable(..., name="v1")
v2 = tf.Variable(..., name="v2")
...
# Add ops to save and restore only 'v2' using the name "my_v2"
saver = tf.train.Saver({"my_v2": v2})
# Use the saver object normally after that.
- TensorBoard: 1. 查看summary_operation文档来了解所有可用的summary操作详细信息; 2. 使用tf.merge_all_summaries来将所有汇总操作合并为一个操作, 然后运行之; 3. 通过tf.train.Summarywriter对序列化的汇总protobuf进行写入磁盘
- 一旦TensorBoard开始运行, 你可以通过在浏览器中输入localhost:6006来查看TensorBoard
- 图表可视化在理解和调试时显得非常有帮助, 图表可视化里有一个Name scoping的概念, 在一个scoping里可以定义几个操作, 这样做是为了便于展示, 因为节点众多时, 不这样做很难一下看到全部节点
import tensorflow as tf
with tf.name_scope('hidden') as scope:
a = tf.constant(5, name='alpha')
W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0), name='weights')
b = tf.Variable(tf.zeros([1]), name='biases')
#结果是得到了三个操作名: hidden/alpha, hidden/weights, hidden/biases, 默认地, 三个操作名会折叠为一个节点并标注为hidden
- 读取数据: feeding, 从文件读取, 预加载数据, 多管线输入
- feeding: python产生数据, 再把数据喂给后端. placeholder配合feed_dict的方式, 其中, 在run()或者eval()函数输入feed_dict参数. 另外placeholder的唯一目的是为了feeding这个数据供给方法
- TFRecords文件是TensorFlow的标准格式, 使用TFRecords文件保存记录的方法可以允许你将任意数据转换为TensorFlow所支持的格式. convert_to_records.py是一个将数据保存为TFRecords文件的程序, 主要的步骤有: 1. 获取数据, 将数据填入到tf.train.Example协议内存块(protocol buffer), 将协议内存块序列化为一个字符串; 2. 通过tf.python_io.TFRecordWriter写入到TFRecords文件. 从TFRecords文件中读取数据, 代码可参考fully_connected_reader.py.
- 批处理: 对于大型数据, 训练过程中通常都需要对数据进行批量处理. 使用tf.train.shuffle_batch函数来通过随机抽取产生batches, 注意里面的参数min_after_dequeue和capacity. 另外, 使用tf.train.shuffle_batch_join函数对不同文件中的样本进行更强的乱序和并行处理.
- tf.train.start_queue_runners: 启动输入管道的线程, 填充数据样本到队列中, 以便出队操作可以从队列中拿到样本, 配和函数tf.train.Coordinator可以在发生错误的情况下正确地关闭这些线程.
- 一个简单的demo
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
print example.eval() #取样本的时候,一个Reader先从文件名队列中取出文件名,读出数据,Decoder解析后进入样本队列。
coord.request_stop()
coord.join(threads)
- 下图中, 首先由一个单线程把文件名堆入队列, 两个Reader同时从队列中取文件名并读取数据, Decoder将读出的数据解码后堆入样本队列, 最后单个或批量取出样本, 这里的图并没有展示样本出队
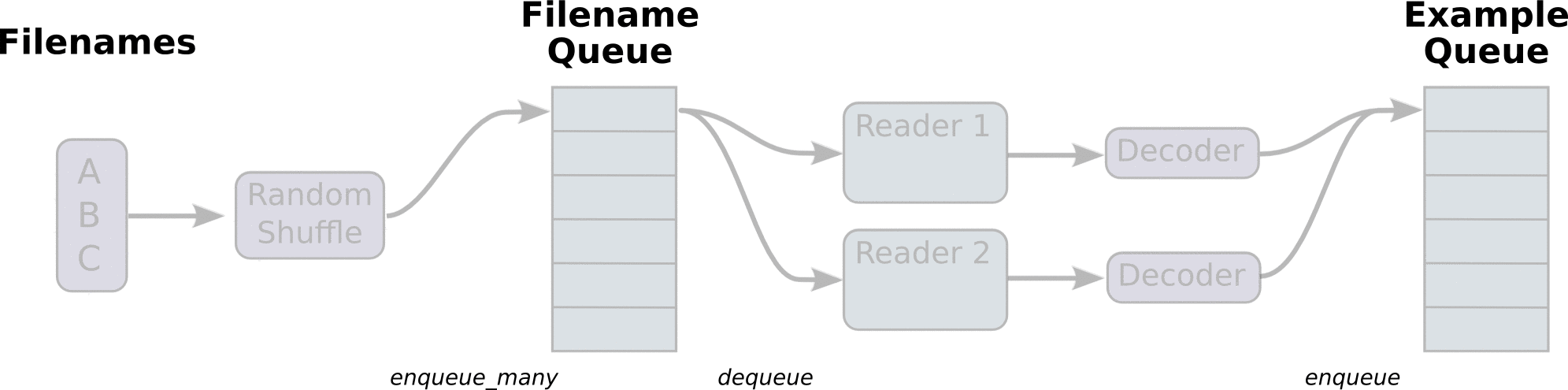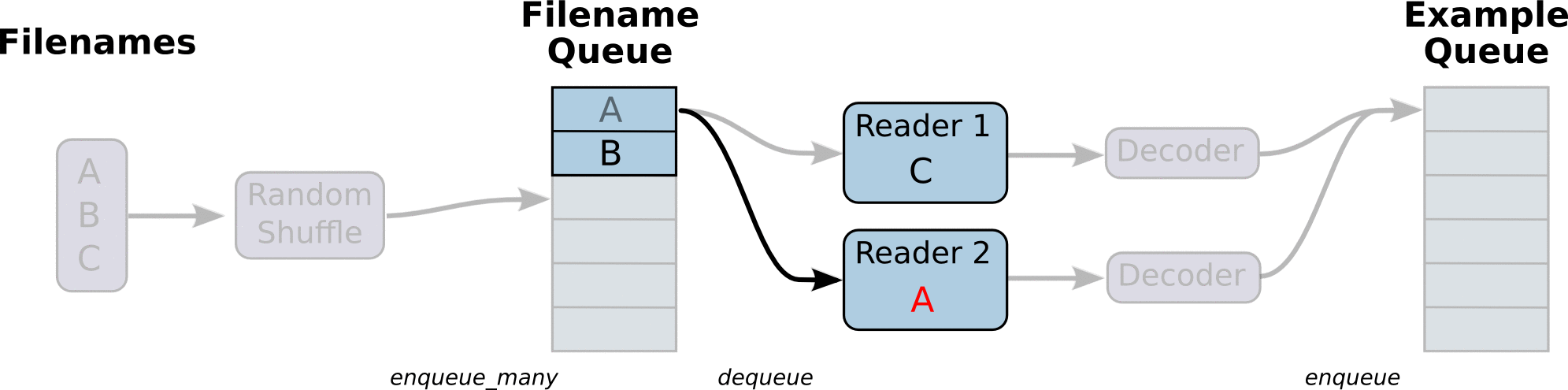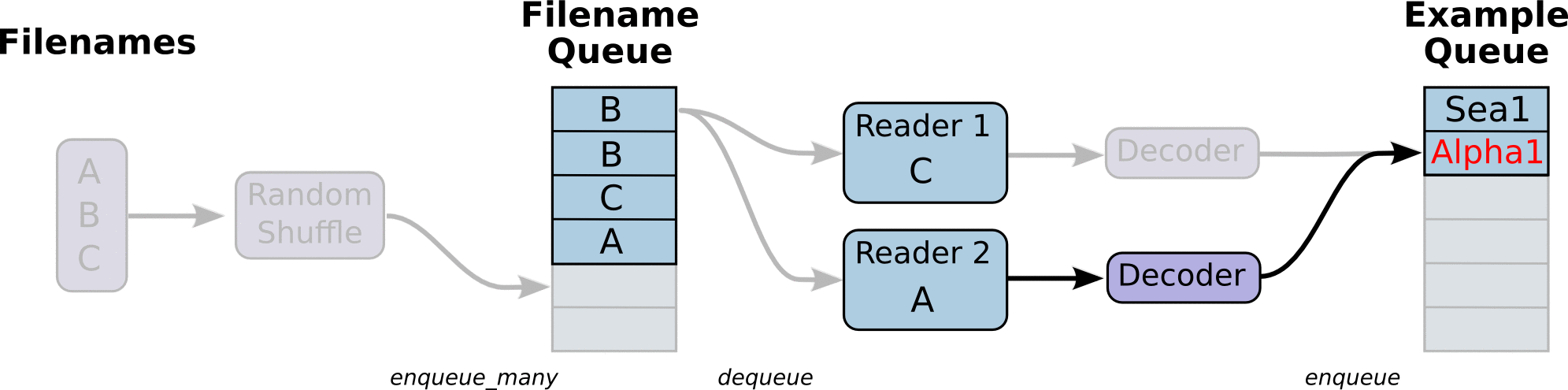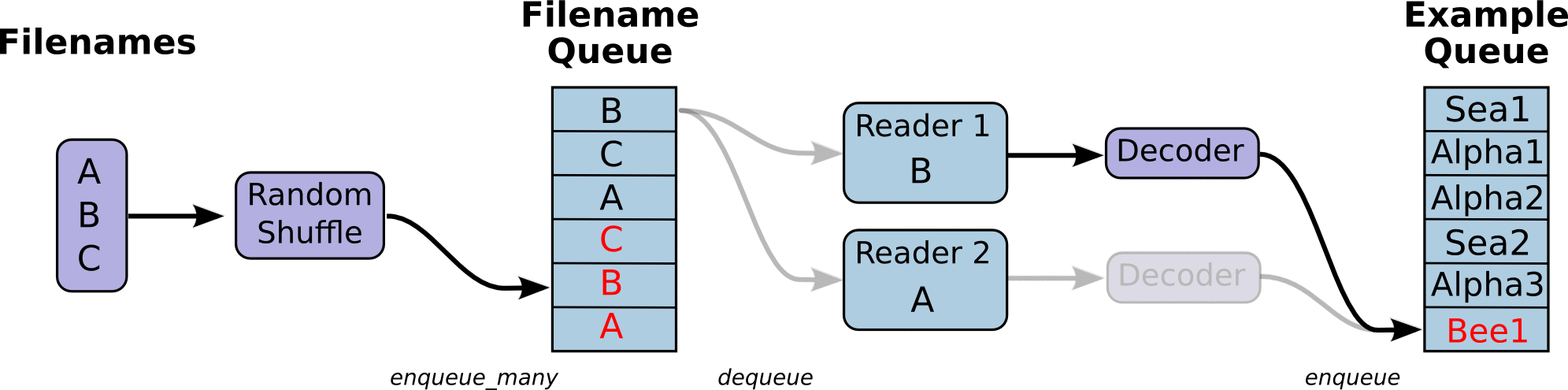
- 使用tf.train.batch()会多加了一个样本队列和一个QueueRunner, Decoder后数据会进入这个队列, 再批量出队
- 使用tf.train.batch_join(), 可以使用多个reader, 并行读取数据, 每个Reader使用一个线程.
- 看下[2, 3]关于普通文件、TF数据的读写代码, 熟悉后看官方文档就足够了
- 线程和队列: 为了感受一下队列, 让我们来看一个简单的例子. 我们先创建一个“先入先出”的队列(FIFOQueue), 并将其内部所有元素初始化为零. 然后, 我们构建一个TensorFlow图, 它从队列前端取走一个元素, 加上1之后, 放回队列的后端. 慢慢地, 队列的元素的值就会增加.

- TensorFlow提供了两个类来帮助多线程的实现: tf.Coordinator和 f.QueueRunner, 从设计上这两个类必须被一起使用. Coordinator类同时关闭多线程并上报异常, QueueRunner类协调多线程并将多个tensor推入队列
- 任何一个线程都可以决定计算什么时候应该停止: 一个线程只需要调用request_stop(), 同时其他所有线程的should_stop()将会返回True, 然后所有线程都停下来了, 即, 一个request_stop, 其他should_stop.
- QueueRunner创建几个线程, 然后QueueRunner使用Coordinator来管理这些线程.
# Create a queue runner that will run 4 threads in parallel to enqueue
# examples.
qr = tf.train.QueueRunner(queue, [enqueue_op] * 4)
# Launch the graph.
sess = tf.Session()
# Create a coordinator, launch the queue runner threads.
coord = tf.train.Coordinator()
enqueue_threads = qr.create_threads(sess, coord=coord, start=True)
# Run the training loop, controlling termination with the coordinator.
for step in xrange(1000000):
if coord.should_stop():
break
sess.run(train_op)
# When done, ask the threads to stop.
coord.request_stop()
# And wait for them to actually do it.
coord.join(threads)
- 线程、队列这部分内容只需要仔细看官方文档即可.
undone
- 自定义数据读取
资源、其他
- 详细了解前三章后可通过这两部分内容对tensorflow进行复习、巩固
查看变量的值
- 在建立graph的时候,只建立tensor的结构形状信息,并没有执行数据的操作, 所以一定要run起来
import tensorflow as tf
t = tf.truncated_normal([3, 3, 16, 48], stddev=00.1)
sess = tf.Session()
print(sess.run(t))
Reference
- 0. Tensorflow中文文档
- 1. TensorFlow数据读取方式
- 2. TensorFlow数据读取方法(该文写了几个文件读写的demo)
- 3. 第十一弹_队列&多线程&TFRecod文件_我辈当高歌(TF数据的读写代码)
Lasagne
特点:
- 简洁已用、易扩展
- 没有隐藏Theano, 直接处理返回Theano expression或python/numpy data types
- 功能实用
- Do one thing and do it well
Reference
- 0. A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction
- 1. Lasagne
- 2. virtualenv
- 3. conda and virtualenv
- 4. 环境隔离
conda and virtualbox
this step is failed for me, ang then i install miniconda2:
bash Miniconda2-latest-Linux-x86_64.sh
I choose when i was asked:
Do you wish the installer to prepend the Miniconda2 install location
to PATH in your /home/lmr/.bashrc ? [yes|no]
[no] >>> no
You may wish to edit your .bashrc to prepend the Miniconda2 install location to PATH:
export PATH=/home/lmr/miniconda2/bin:$PATH
Thank you for installing Miniconda2!
#### Base level usage of conda
conda create -n conda_python3 python=3
source activate conda_python3
source deactivate
conda info -e
- conda: 可对Python、R、Ruby、Lua、Scala、Java、Javascript、C/C++、FORTRAN的包、依赖、环境进行管理(即在conda环境中管理这些语言的包)
- pip: 允许你在任何环境中安装pthon包, 关注python
- conda和virtualenv最好独立使用, 尽量避免嵌套安装, 这样会和pip有更好的兼容性
- wheel没有conda的依赖处理能力
- virtualenv: 构建独立的python环境, 解决包之间的依赖、版本、权限的问题(只针对python)
总结: conda虚拟环境容易迁移, 可以在有外网的电脑生成后打包上传到无网的服务器上使用. pip是个包管理器、virtualenv是环境管理器、而conda两者兼顾.
conda目录结构:
- ROOT_DIR: Anaconda或Miniconda的安装位置
- PKGS_DIR或/pkgs: 解压位置, 每个包位于二级目录; 用于在conda环境里进行link
- /envs: conda环境的系统路径
conda环境:
- 一个环境就是一个目录, 这个目录包含一些特定的(版本)conda包
- 可以在各个环境中自由切换
- 可以通过发给别人一个environment.yaml来共享你的conda环境
conda包以及安装:
- 一个conda包就是一个tarball文件(可能包含系统级库、Python或者其他模块、可执行文件)
- conda包从remote channels(conda包的URL)下载、更新
- conda命令会默认搜索一些remote channels, 另外, 默认搜索行为是可以更改的, 也就是说你可以自己指定一批默认URL
- 所有平台的包格式是一致的, 即: *.tar.bz2
- conda install [packagename]: 包的安装命令
- info/: 包里会有一个这样的路径, 里面是metadata
- 安装原理: 文件(info/里的文件除外)被提取到有install前缀的路径里; 安装conda包到conda环境就是解压缩、放到环境/路径里(同样的方式处理其依赖)
conda创建独立的环境:
- 创建环境、并安装包、启用、查询
#snowflakes是环境名, biopython是包名
conda create --name snowflakes biopython
#启用
source activate snowflakes
# 查询有哪些环境
conda info --envs
# 对python的管理
conda create --name snakes python=3.5
包管理:
- 查询、安装
#查询包, 可以输入一部分名字, 然后会列出与之相关的包名以供选择安装
conda search xxx
#安装
conda install xxx
#列出当前环境所有安装的包
conda list
- 在有其他python或包的环境下安装conda: 不需要卸载已有安装, 正常安装即可
conda的静默安装:
- -b选项: 不会修改~/.bash_profile
- 启动的时候需要export PATH=”$HOME/miniconda/bin:$PATH”、source $HOME/miniconda/bin/activate
wget https://repo.continuum.io/miniconda/Miniconda3-3.7.0-Linux-x86_64.sh -O ~/miniconda.sh
bash ~/miniconda.sh -b -p $HOME/miniconda
position_c: Configuration
卸载conda:
rm -rf ~/miniconda
others:
- conda search –canonical | grep -v ‘py\d\d’: 找出不是 pip和virtualenv可以管理的python包
深度学习开发环境
远端
- Docker目前并不能让你最有效地使用任何一个 NVIDIA 的 GPU 硬件或者 CUDA 驱动程序, 所以使用Nvidia-docker, 它在常规的Docker命令之上, 它还提供了一些选项, 可以让你更有效地管理你的NVIDIA GPU 硬件.
- SLURM可用于多同事使用一台机器, 对权限有更好的控制
本地
- OS X Fuse
Reference
深度学习开发环境
- [2.]深度学习开发环境配置
- [[3.]深度学习开发环境调查结果公布,你的配置是这样吗]](https://www.jiqizhixin.com/articles/2017-06-26-9)
转载请注明:Mengranlin » 点击阅读原文