
本文对人脸对齐涉及到的一些方法进行总结, 并在最后介绍我在这个任务上的一些工作.
目录
CNN在人脸对齐上的应用
2014-Facial Landmark Detection by Deep Multi-task Learning(TCDCN)
TCDCN将人脸标记点检测任务与其他相关任务(related tasks)联合起来一起优化. TCDCN构造了一个task-constrained loss function来使related task的error得以反响传播来改善标记点检测任务. 为了调和不同难度、不同收敛速率的任务, 专门设计了任务级的(task-wise)停止规则来加速收敛. TCDCN从raw pixels中学习feature representation而不是预定义的HOG人脸描述子.
SGD对于单一任务的学习是有效的, 但是对于多任务的学习却没那么容易, 原因在于: 不同任务具有不同的收敛速率. 现有的解决这个问题的方案为: 利用任务之间的相关性, 例如: 学习一个所有任务权重的协方差矩阵. 然而, 这个方法的局限在于需要要求所有任务的loss function是相同的, 可见对于具有不同loss function的多任务系统显然是不适用的. 此外, 当weight向量的维度很高时, 计算协方差矩阵的代价是很高的.
TCDCN提出early stop规则来及时停止辅助任务的学习以防止其对training set过拟合. 这里有一点要注意early stop规则的regulalization与惩罚权重的regulalizaion是不同的. early stop规则综合考虑了任务在training error的下降趋势以及在validation set上的泛化能力。也就是希望达到这样的目的:如果在training set上的error下降很快则倾向于继续训练.
网络结构: 输入是40x40的灰度人脸图像, 4个卷积层, 3个池化层, 1个全连接层. 每个卷积层会输出多个feature map. 卷积层中的activation function是absolute tangent function. 在池化阶段, 将max-pooling应用在feature map的non-overlap regions. 最后全连接层输出主要任务、辅助任务共享使用的feature vector. 结构如下图:

小结: TCDCN相对于cascade CNN具有更好的检测精度、更低的计算消耗. TCDCN模型小, 实时性较好, 可以尝试将其整合到我的工作中, 试试效果. 接下来对较早的cascade CNN文章进行解读、分析.
2013-Deep Convolutional Network Cascade for Facial Point Detection(cascade CNN)
cascade CNN有三个level的卷积神经网络, 第一层网络(level 1)用于整体形状的预测, 接下来的两层(level2、3)是精细化的修正. 因此, 所谓的Multi-level regression的含义是: level 1对facial landmarks做初始预测, level 2和level 3提取初始预测周围的图像(local patch)作为input, 然后做精细化调整(对应着文中提到的Adjustment, 也可以认为后面的level是对形状差进行预测), 另外, 补充一点: 在cascade的框架下, patch size 和search range逐级缩小. 本文的网络结构如图3(a-b), 其中图2a为cascade CNN(3-levels)的整体网络结构, 图2b为cascade CNN所用到的子网类型, 图2c为最深的F1子网的结构.
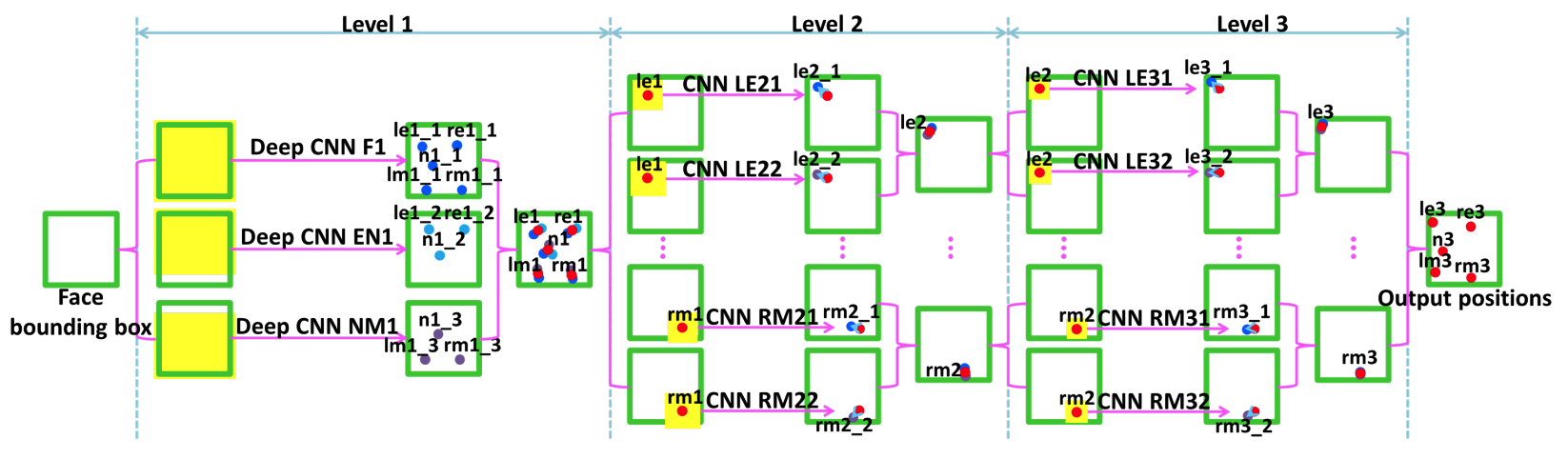
level 1的网络结构由子网S0、S1构成, 具体来说: F1 采用了S0, EN1和NM1采用了S1; level 2、3的网络结构由子网S2构成; 而且level2、3是与level1类似的浅层结构. 另外, EN1和NM1的网络结构与F1类似, 只是对应的input region不同. 因此, 下面详细描述网络结构最深的F1.

F1是由四层卷积+绝对值非线性操作+局部共享权值构成的深度卷积层, 其中, F1中立方体的length代表feature map的个数, 而[width x height]代表map的大小. 另外, F1使用了 locally sharing weights , 而不是 globally weight sharing , 这主要因为后者更适用于语义接近的feature. 例如: 虽然眼睛和嘴巴可以共享一些 low-level 的特征如: edges, 但是他们在 high-level 上的feature差异很大. 因此, 对于input包含语义差异较大的region的情况(如: high-layer-feature )更适合采用 locally sharing weights (eg: the idea of locally sharing weights was originally proposed for convolutional deep belief net for face recognition). 此外, 补充一点: level 2、3之所以是浅层结构是因为他们提取局部features, 因此没必要设计成deep结构与局部权值共享.
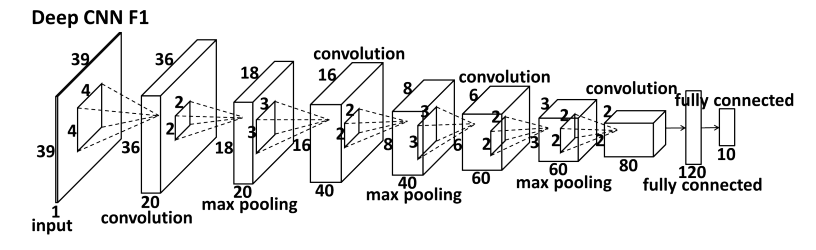
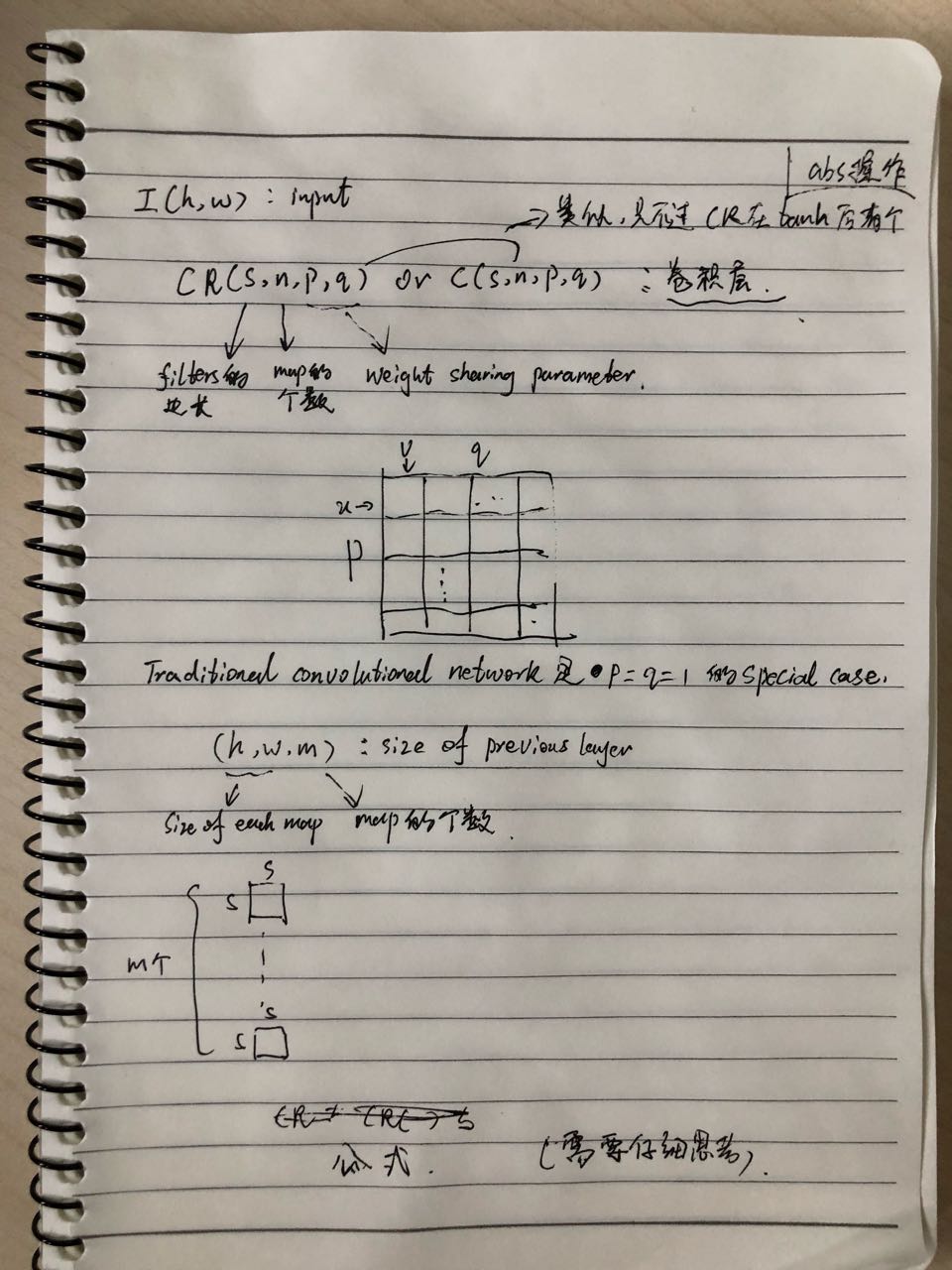
细节: convolutional layer(CR(s, n, p, q))如图3a, pooling layer(P(s)) and Fully connected layer(F(n))如图3b. 输入: F1 将整个人脸图像作为输入并输出5点坐标, EN1将人脸的顶部和中间部分图像作为输入并输出3点坐标(眼睛、鼻尖). level2、3将前一层预测的point附近的image region作为输入并输出形状增量. 注意: level2、3对于同一个点使用了两个不同的image region进行预测, 然后merge这两个结果, 同时level3 中的image region要比level2中的小. 训练: 对于level1, 我们根据bounding box做了translation和rotation操作. 在level2、3, 我们将truth position进行随机水平和垂直平移来获得region, level2的最大平移限上限为0.05、level3为0.02, 这里的距离够根据bounding box进行了规范化. 训练过程中需要更新的网络参数为: weight(w)、gain(g)、bias(b), 学习的方法为SGD.
小结: S0 与S3~5结构类似, 只是深度不同, 从结果可以看出深度增加可以改善算法性能. S6~7均与S0层数相同, 但是S6没有absolute value rectification, S7采用的是全局权值共享, 也就是说所有的convolutional layer的权值都一样. 从实验可知: absolute value rectification和locally sharing weights非常重要. 论文猜测: 高阶特征的共享性质要弱于低阶特征. 基于这个猜想可推测: a)locally sharing weights对于较高layer比较重要,b)仅在较低layer使用locally sharing weights会影响性能或者说低层layer更适合globally sharing weights. 实验说明采用cascade的方式可以提高性能.
我的工作
我关注的问题是运动下的人脸标记点标注问题, 如果直接将这些单帧人脸特征点标记方法应用于实时人脸标记点跟踪的场景, 就会出现如下问题:
- 静态抖动: 在人脸保持静止或者微弱运动时,可以明显的看到人脸特征点抖动的情况,这主要是由于物理硬件以及光照变化带来的图像噪声引起的.
- 运动不平滑: 在运动时, 人脸检测框抖动或者检测不到人脸引起的.
尤其应用在手机上的时候, 还要格外注意:
- 时间性能
- 模型文件的大小
考虑到实时性的问题, 我以One millisecond face alignment with an ensemble of regression trees(ESR)为基础设计了可以捕捉时域信息的模型, 然后, 再通过常规的一些后处理策略加强跟踪效果, 同时, 针对跟踪问题固有的fitting现象, 加了reboot机制. 细节可参考我的论文.
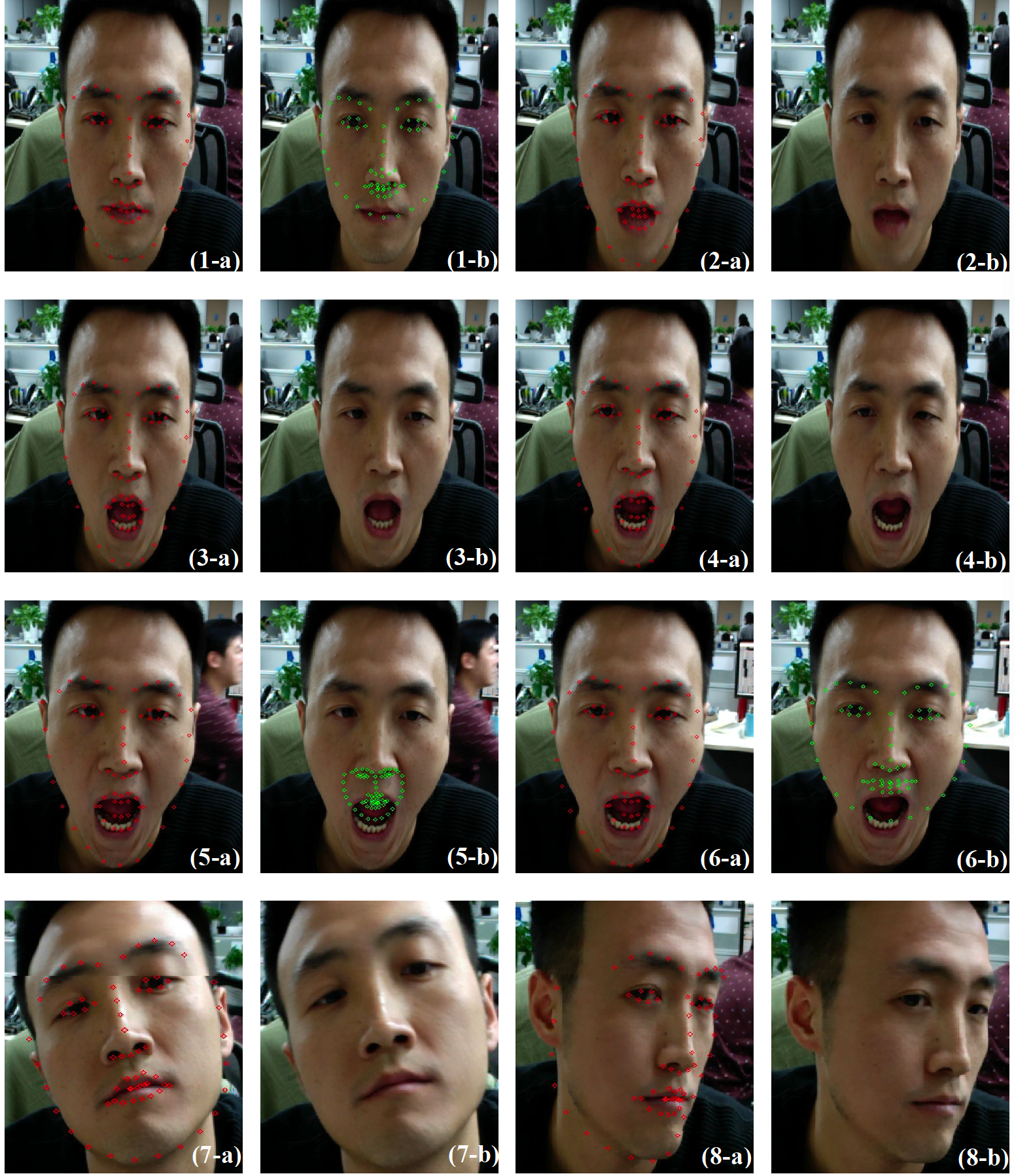
其中, 红色代表优化后的效果, 绿色代表优化前的效果. 我们的方法对于大角度转动、夸张表情的标记都比优化前有了较大的提高. 另外, 从视频里的跟踪表现来看, 抖动情况也明显减少, 运动的平滑性也提高了. 但仍有不足的地方, 比如精细化的表情, 如眯眼、微动嘴角, 此外, 抗遮挡的能力也较差.
待梳理
- 怎样将论文中的辅助任务整合到普通模型中(仔细回顾下TCDCN)
- TCDCN替换我的基础模型效果会怎样
Reference
Source:
- 1. train
- 2. test
- 3. Cascaded CNN 方法寻找人脸关键点
- 4. 实践总结
- 5. source code(TCDCN) by one reader
- 6. 香港中文大学多媒体实验室
Papers:
- 1. 2013-cvpr-Deep Convolutional Network Cascade for Facial Point Detection(cascade CNN)
- 2. 2014-eccv-Facial Landmark Detection by Deep Multi-task Learning(TCDCN)
- 3. 2014-cvpr-One millisecond face alignment with an ensemble of regression trees
- 4. 2015-cvpr-Face Alignment by Coarse-to_fine Shape Searching
- 5. 2018-mine-An Efficient Method Utilizing Temporal Correlationship for Real-time Face Alignment
Blogs:
转载请注明:Mengranlin » 点击阅读原文