
定期存档
目录
FFT
对于fft, fftshift等常规操作的理解:
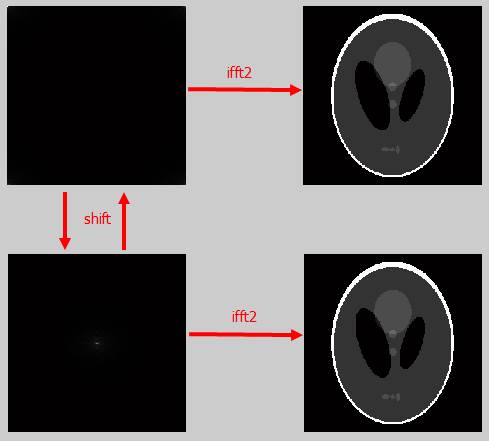
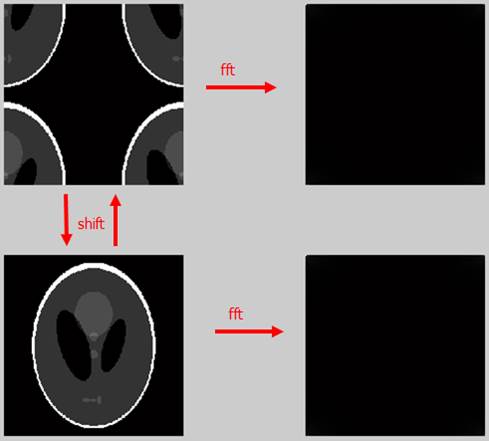
从右侧看长的一样, 但是从左侧看, 根据视觉的判断显然知道左侧的数据不一样(经过shift后是一样的), 并且由于傅里叶变换是一对一的变换, 所以可以知道右侧数据是不同的. 同理如下图: 基于傅里叶变换的线性特点, 熟练使用下面的操作:
fft(A) = fft(I*A) = I * fft(A) = fft(I)*A
数字信号处理&信号与系统[common sense]
延迟:
- 在数字信号处理的硬件设备中, 延迟实际上是由一系列的移位寄存器来实现的
互相关:
- Rxy(m): x信号向右移位m后与x信号相乘再求和(等价于y信号左移然后相乘再相加), 自相关函数Rxx(m)定义与此类似, 这是一个特别的互相关.
- 互相关函数Rxy(m)衡量两个信号x, y的相似性, 自相关函数Rxx(m)衡量信号x与其时移后的信号的相似性
- 物理意义: 相关函数只是反映了两个信号的相似性, 与系统无关; 卷积反映了线性时不变系统输入, 输出和单位冲激响应的关系,是与系统有关的.
- 实信号的自相关为实偶函数,如果为复信号,则r(-m)与r(m)是共轭的
- 不移位时,自相关最大
- 对于能量信号,如果移位太大了,那么自相关会变小,当移位趋向无穷大时,自相关为0
- Rxy(m)不是偶函数,,但是有Rxy(m)=Ryx(-m)
- 互相关函数绝对值$|Rxy(m)|$小于等于两信号能量乘积的开方:$|Rxy(m)|<=sqrt(Rx(0)Ry(0))=sqrt(ExEy)$
- 对于两个能量信号,如果移位太大了,那么互相关会变小,当移位趋向无穷大时,互相关为0
- 经验:噪声的自相关函数Ru(m)主要在m=0出有值,当$|m|>0$时,应衰减的很快,信号与噪声的互相关函数应该很小,建模时可考虑将两者的影响忽略
- 自相关可用于噪声中信号的检测,信号中隐含周期性的检测,信号相关性的检测,信号时延长度的检测.
卷积:
- 理解1:二维理解法(信号移位后求加权和),注意:x(n)*y(n),n做横轴,m做纵轴;或者说这叫做一n的方式来思考信号
- 理解2:x(n)*y(n)就是将x信号翻转,右移n个单位,然后与y信号相乘再相加(求和);注意,这种理解方式与互相关统一起来了
相关vs卷积:
- 统一的理解方式中,函数的字变量只是个移动量,或者说不是两个信号的自变量;而卷积的二维理解方式中,函数的自变量确是主体,是作为后面一个信号的自变量的,也就是上面的横轴
- 统一理解方式:互相关:第一个信号右移,相乘相加;卷积:第一个信号翻转右移,相乘相加
- 卷积的二维理解方式:x(n)*y(n)中,n作为x信号的自变量,然后右移m个单位(m有无穷多个,也就说有无穷多个x移位信号),y(m)作为这些信号的权值,将这些信号加权求和后得到最终的卷积信号
功率:
- 可能是实际物理上的功率,或者信号数值的平方;
时域功率:
- 描述信号或者时间序列f(t)的能量如何随着时间分布,数学定义为为f(t)的幅度(模)的平方
谱密度(能量谱密度):
- 描述信号或者时间序列f(t)的能量如何随着频率分布,或者可以叫谱密度为频域上的功率(与时域功率联系理解);数学上的定义就为f(t)的傅立叶变换的幅度(模)的平方
功率谱密度:
- 描述信号或者时间序列的功率是如何随着频率分布的,可叫做信号f(t)的时域功率p(t)的傅立叶变换
- 如果信号可以看作是一个平稳随机过程,那么信号的功率谱就是信号的自相关函数的傅立叶变换;根据该属性,有关功率谱的方法均可应用于自相关
实验笔记:
- k_up,k_down,分别是取得的部分编码线,两个采样有重叠,在单独进行ifft2的时候得到两张空间域图像,两张图像都会出现模糊,但是当把两张空间域图像相加的,然后再归一化显示,得到的效果与ifft2下的kt(:,:,1)是一样的.
循环卷积与线性卷积:
- 分析时域离散线性时不变系统或者进行滤波操作的时候,需要计算两个序列的线性卷积。然而DFT只能直接计算循环卷积,如果想使用DFT计算线性卷积,就要研究线性卷积和循环卷积之间的关系。循环卷积与线性卷积的特点:
- 循环卷积: 有移位,有补充,有延拓(因此是周期的);
- 线性卷积: 有移位,无补充,无延拓;
overlap-add与overlap-save:
- 这两个算法都是计算长序列卷积的,思想都是分段卷积,overlap-add进行分段卷积时用的是线性卷积,overlap-save进行分段卷积时用的是循环卷积. 设计这两个算法的时候,只需要考虑:
- 原始长序列进行卷积的情况
- 两种分段卷积算法的情况。
- overlap-add算法分段卷积时每段卷积结果的前半段(M-1)会出现缺失的情况[第一段除外];
- overlap-save算法分段卷积时每段卷积结果的前半段会出现混叠的情况;
MRI循环卷积:
- 磁共振成像的混叠现象可以用循环卷积的特点来解释
- 线性卷积可以用循环卷积来求解[可分为时域方法和频域方法];具体的方法为:在xn后面补充相应数量的0来构造周期为N+M-1的循环卷积,这样一般卷积就是循环卷积的一个周期的值
- 原理:用0来撑开xn,以避免循环卷积带来的混叠
定点计算
将浮点算法转化为定点算法,首先就要把所有的小数经定标转化为整数。比如浮点算法中有一个浮点数组为[ 0.25 0.5 1.125 5.75 7.0 ],用二进制表示为 [ 0.01 0.1 1.001 101.11 111.0 ]。将数组各分量左移三位,得[ 10 100 1001 101110 111000 ],十进制表示为[ 2 4 9 46 56 ]。小数点位置在第3位,此数组中的各分量都是Q3格式,这就是定标的过程。注意:十进制小数和二进制小数并不是一一对应的,也就是有些十进制小数没有与其对应的二进制小数换种说法就是,二进制小数是十进制小数的离散点.
语音信号处理
基本概念以及历史:
- 音高:人耳对声音调子高低的主观感受;客观上音高大小主要取决于声波基频的高低,频率高则音调高.
- 音色:一切物体发声的原理都是振动出声由空气传出,那在物体振动的时候出来的频率都是一个波形,这个波总可以分解为一系列不同频率正弦波的叠加,含一个基波和许多谐波,即内含各种频率成分,音色的不同,就是这些谐波的含量都不相同.
- 声音的频率:声波每秒的振动次数称为频率,如图1,频率在20hz~20khz之间称为声波;频率大于20khz称为超声波;频率小于20hz称为次声波。超声波和次声波人耳是听不到的,地震波和海啸都是次声波。有些动物的耳朵比人类要灵敏得多,比如蝙蝠就能”听到”超声波。在音频信号中,通常又把300hz到3400hz的频率范围成为“语音信号”,对应了人的发声频率。高频和低频是相对的,在语音范围中,通常把1000 hz以上的区域称为高频区,500 hz -1000 hz的区域称为中频区,低于500 hz的区域称为低频区。电话信号只覆盖了人的发生频率范围,从200hz到3400hz,AM广播达到7000hz,FM广播达到15khz,CD音质最好,覆盖了全部人耳能够听到的频率范围。
语音信号的数字表示可以分为两类: 波形表示 , 参数表示 .
- 波形表示:仅通过采样和量化保存模拟语音信号的波形
- 参数表示:将语音信号表示为某种语音产生模型的输出,是对数字化语音进行分析和处理后得到的。
声音的编码:
- 波形编码:波形编码是在时域上进行处理,对模拟语音按一定的速率抽样,然后将幅度样本分层量化。波形编码的基本过程可以概述为:采样——量化——编码。为了用有限的bit数表示所有的采样值,需要对采样后的离散信号进行量化处理,量化可以分为均匀量化和非均匀量化。量化完成后输出的数据就是常说的PCM数据了。在最早的电话系统中,对语音信号8khz采样,每秒产生8000个样点,对每个样值8bit编码,那么一路话音数据的码率就是8000*8=64kbps(码率就是一秒内总的bit数,码率也叫比特率)
- 参数编码:参数编码是利用语音信息产生的数学模型,提取语音信号的特征参量,并按照模型参数重构音频信号。从原理上讲,LPC是通过分析话音波形来产生声道激励和转移函数的参数,对声音波形的编码实际就转化为对这些参数的编码,这就使声音的数据量大大减少。在接收端使用LPC分析得到的参数,通过话音合成器重构话音。合成器实际上是一个离散的随时间变化的时变线性滤波器,它代表人的话音生成系统模型。时变线性滤波器既当作预测器使用,又当作合成器使用。分析话音波形时,主要是当作预测器使用,合成话音时当作话音生成模型使用。随着话音波形的变化,周期性地使模型的参数和激励条件适合新的要求。它只能收敛到模型约束的最好质量上,力图使重建语音信号具有尽可能高的可懂性,而重建信号的波形与原始语音信号的波形相比可能会有相当大的差别。这种编码技术的优点是压缩比高,但重建音频信号的质量较差,自然度低,适用于窄带信道的语音通讯,如军事通讯、航空通讯等。美国的军方标准LPC(线性预测编码)-10,就是从语音信号中提取出来反射系数、增益、基音周期、清/浊音标志等参数进行编码的。
- 混合编码:将上述两种编码方法结合起来,采用混合编码的方法,可以在较低的数码率上得到较高的音质。它的基本原理是合成分析法,将综合滤波器引入编码器,与分析器相结合,在编码器中将激励输入综合滤波器产生与译码器端完全一致的合成语音,然后将合成语音与原始语音相比较(波形编码思想),根据均方误差最小原则,求得最佳的激励信号,然后把激励信号以及分析出来的综合滤波器编码送给解码端。这种得到综合滤波器和最佳激励的过程称为分析(得到语音参数);用激励和综合滤波器合成语音的过程称为综合;由此我们可以看出CELP编码把参数编码和波形编码的优点结合在了一起,使得用较低码率产生较好的音质成为可能。通过设计不同的码本和码本搜索技术,产生了很多编码标准,目前我们通讯中用到的大多数语音编码器都采用了混合编码技术。例如在互联网上的G.723.1和G.729标准,在GSM上的EFR、HR标准,在3GPP2上的EVRC、QCELP标准,在3GPP上的AMR-NB/WB标准等等。
名词解释:
- VBR:Variable Bitrate(动态比特率):没有固定的比特率,压缩软件在压缩时根据音频数据即时确定比特率,特点:以质量为前提兼顾文件大小。
- CBR:constant Bitrate(常数比特率):指文件从头到尾都是一种位速率,它压缩出来的文件体积很大,并且音质相对VBR,ABR并没有显著提升。
- ABR:Average Bitrate(平均比特率):是 VBR的一种插值参数。LAME针对CBR不佳的文件体积比和VBR生成文件大小不定的特点独创了这种编码模式。ABR在指定的文件大小内,以每50帧 (30帧约1秒)为一段,低频和不敏感频率使用相对低的流量,高频和大动态表现时使用高流量,可以做为VBR和CBR的一种折衷选择。
- 采样率:单位时间内对音频信号进行采样的次数.它以赫兹(HZ)或千赫兹(KHZ)为单位.通常来说,采样率越高,单位时间内对声音采样的次数就 越多,这样音质就越好;MP3音乐的采样率一般是44.1KHZ,即每秒要对声音进行44100次分析。
音乐格式五花八门,多如牛毛,但不外乎分为两大类:
- 音乐指令文件(如MIDI),一般由音乐创作软件制作而成,它实质上是一种音乐演奏的命令,不包括具体的声音数据,故文件很小
- 声音文件,是通过录音设备录制的原始声音,其实质上是一种二进制的采样数据,故文件较大。
从播放形式上,声音文件还可以分为: 音频流 和 非音频流. 前者能够一边下载一边收听,比如“.WMA”、“.RA”、“.MOV”等,后者则不能。所谓流媒体技术就是把连续的影像和声音信息经过压缩处理后放上网站服务器,让用户一边下载一边观看、收听,而不需要翟畸个压缩文件全部下载到自己机器后才可以观看的技术。
- 声道:我们经常听说的单声首、立体声,指的就是这里要讲的声道。声道是指声音在录制或播放时在不同空间位置采集或回放的相互独立的音频信号。
常见的声道数有单声道(Mono)、立体声(Stereo)、5.1声道。顾名思义,单声道就是只有一个声道,声音听起来缺乏位置定位,而立体声正好弥补了这一缺点。立体声即双声道,通过在声音录制过程中被分配到两个独立的声道,从而达到了比较好的声音定位效果。而5.1声道则更进一步强化了这种位置感,使人感觉环绕在声音的现场中。5.1声道的输出包括中央声道、前置主左/右声道、后置左/右环绕声道,以及所谓的“0.1”即重低音声道。
- 语谱仪:用图形来表示语音信号时变谱。
- 封装格式:就是把视频文件和音频文件打包成一个文件的规范,如avi,rmvb,mp4,flv,mkv。仅仅靠看文件的后缀很难看出具体使用了什么视音频编码标准,总的来说,不同的封装格式之间差距不大,各有优势。有些封装格式支持的视音频编码标准十分广泛,应该算比较优秀的封装格式,比如mkv;而有些封装格式支持的是音频编码标准很少,应该属于比较落后的封装格式,比如RMVB。
音频技术主要包括以: 封装技术,视频压缩编码技术,音频压缩编码技术,流媒体协议技术(网络传输). 只有avi不支持流媒体(即边下边播),该封装给是通常用于bt下载影视,因此我们下载的电影可以是avi格式mp4,mkv,flv都可用于互联网视频网站,因此从视频网站下载的视频基本是这三个格式ts封装格式用于IPTV和数字电视RMVB是比较老的一种封装格式,用于BT下载影视,因此下载的电影也可是这种格式。
回声: 回声路径的时延主要由 系统时延 和 扬声器到麦克风的传播时间 构成的。
- 系统时延:缓存在音频设备中准备播放和录制的数据按理来说,增加适应滤波器的抽头系数(filter taps)可以处理时延的问题,但是抽头系数的增加就会降低收敛速度,因此在滤波器进行滤波之前,要对时延进行修正,如果时延修正的好,滤波器的系数就不需要设计的很长。
通常采用的时延估计方法为 互相关检测方法 :
- 互相关检测方法: 该方法的原理就是计算远端信号和近端信号的互相关性,互相关最大所对应的时延就为所估计的时延.
互相关检测方法的缺点:
- 在时延估计之前如果不对信号做任何的处理,该方法对回声路径的改变敏感,因此在估计之前对信号做一些修改(如使用时域包络),会增加算法的鲁棒性;但是无论是否对信号进行修改,只要是基于相关性的算法,总有一个缺点,那就是:当两个信号存在线性相关性的时候,相关性算法执行效果比较好,但是如果发生非线性扭曲比如频率耦合的时候,相关性算法的鲁棒性就不好了。
- 在时延检测过程中,计算复杂度是一个主要的影响因素 。通常一个系统的时延可达到300ms,在这种情况下,假如采样频率为16kHz并且没有先验知识(priori)的情况下,为了能达到可以检测300ms时延的上限,那么就需要有4800(300*(16000/1000))个候选点待处理;此外互相关需要长序才能有比较好的执行结果,无疑,这又增加了算法的复杂度。有许多中方式降低算法的复杂度,比如通过下采样或者使用稀疏搜索策略,然而采用这种方式就需要我们在算法复杂度和精确度之间做一个平衡(trade-off),这样的话,如何在不降低性能的情况下来降低精确度是我们要面临的问题在AES和AEC中,处理的是频域数据并且处理的基本单位是采样点块,这就意味着时延估计的分辨率是采样点块而不是采样点,因此零时延误差意味着远端信号和近端信号的对齐是块的对齐(block-wise),这就说明,采样点级的对齐是无法保证的。
aec:
两种声学回声:直接回声,间接回声.
- 直接回声:扬声器出来的声音没有经过任何中间过程而直接进入麦克风,特点:回声的延迟时间非常短,相对来说对通话质量的影响就不太明显
- 间接回声:扬声器出来的声音经过很多的中间处理过程,如在墙壁等物体上经过多次的反射,最终全部叠加到麦克风之中,形成了一个回声的集合,同理可知,这种回声的延迟时间比较长,通常都在50到300毫秒左右,进而会引起滤波器的阶数变高,对通话质量的影响也变得尤为明显。
在实际的回声消除过程中,间接回声才是真正的关键与难点。间接回声的一种场景:
- 当用户使用手机或者免提功能时,采集到的声音信号经过很多次的空间反射最终叠加到话筒中去这种声学回声比电学回声的复杂度要高得多,主要是因为从听筒出来的声音有很多的传输和反射路径,从而能够将时延和幅度不同的语音信号全部传送到话筒中去。由于现在手机尺寸越来越小,信号从听筒出来到话筒直接耦合,还有通过用户的反射都比较大,甚至还有的存在空间反射。这一过程产生的回声在移动通信系统中,经过若干次的处理和编码解码工作,能够产生很大的时延。如果不消除这种回声,当与用户通话的时候便会听到自己的回声。一般来说,各种回声消除设备距离回声源越近,那么回声消除的效果就越明显。
IP语音回声的特点:
- 回声源复杂。
- 回声路径的时延大。
- 回声路径的时延抖动大。[因为传输和反射的路径比较多]
回声消除原理:模拟回声,然后扣除回声.
- 具体来讲:首先预估回声路径中的相关特征参数,接着形成一个模拟的回声路径,然后再计算出模拟的回声信号,最后再从接收的信号当中扣除该信号,从而实现回声消除。途中x(n)表示近端信号,y(n)表示远端信号,r(n)表示真实的回声路径形成的回声,D端叠加有不期望的回声。回声消除器将接收到的远端信号当作参考信号,然后依据自适应滤波器产生的回声估计值r1(n),将r1(n)从近端信号中扣除,这样便计算出近端传出去的信号u(n)=x(n)+r(n)-r1(n),理想情况下,回声经过回声消除器处理后,残留的回声误差几乎为0,从而能将回声真正的消除。
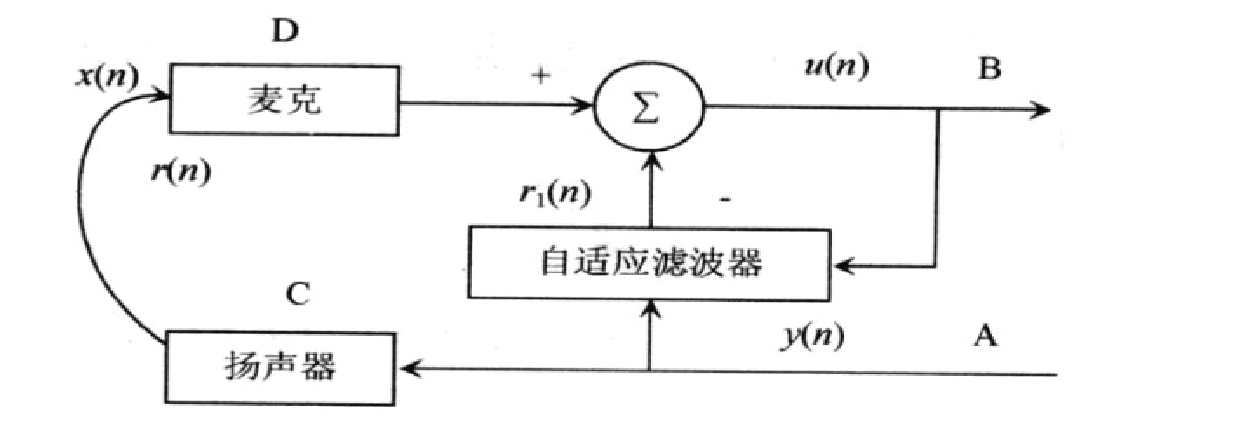
自适应回声消除器有两个关键的组成部分:
- 自适应滤波算法
- 双端语音检测算法(三种语音状态:近端讲话,远端讲话,双端讲话。)
经典自适应回声消除算法:
- LMS(最小均方算法)
- NLMS
- Howells-Applebaum
- 最小二乘算法(LS)
- 递推最小二乘算法(RLS)
- 采样矩阵求逆算法(SMI)
- 正交投影算法
导致因特网语音延迟的来源主要有三种:
- 语音压缩延迟(比较主要的时延)
- 系统处理延迟
- 分组传输延迟
系统处理延迟:对语音包的封装时延及其在缓冲区的缓冲时延,简单的理解就是编码后到发包前的时间段. 判别aec算法好坏的标准:收敛速度快,计算复杂度低,稳定性好,失调误差小.
通信
从研究信息的传输角度来讲,通信的有效性和可靠性是主要的矛盾,有效性体现传输的速度问题,可靠性体现传输的质量问题.
- 码元速率,传码率:单位时间传送 码元 的数目
- 传信率,比特率:单位时间内传递的平均信息量或比特数
- 频带利用率:单位带宽的传输速率(频带利用率 = 传码率/带宽 or 频带利用率 = 比特率/带宽)
通信系统的可靠性可用差错率来衡量,差错率常用误码率和误信率来表示:
- 误码率:码元在传输过程中,被传错的概率(p = 错误码元数/传输总码数)
- 误信率:错误接收比特率的概率(p = 错误比特数/传输总比特数)
工具、ndk、android
NDK:
- NDK(Native Developmengt Kit)是一个需要在linux环境下才能编译生成其他平台可运行的二进制文件的开发工具集. 通俗理解:a).跑在linux上的生成windows可执行文件的工具集;b)是一个编译工具.
cygwin:
- cygwin是一个在windows平台上运行的unix模拟环境,它对于学习unix/linux操作环境,或者从unix到windows的应用程序移植,非常有用。通过它,你就可以在不安装linux的情况下使用NDK来编译C、C++代码,也就是说如果在linux平台上就可以直接只用NDK
JNI(Java Native interface)提供api
- 实现java和其他语言的通信,也就是说JNI就是一个adapter,第三方应用是通过JNI来调用自己的C动态库
JNI与NDK
- JNI是java语言提供的java与c/c++互相沟通的机制,它是java的特性,与android无关,在PC上开发java的应用,如果运行在windows平台上使用JNI是经常的,比如读写windos的注册表
- NDK是google为android开发者推出的,帮助Android开发者通过C/C++本地语言编写应用的开发包;NDK是一些列工具的集合(八廓交叉编译工具),帮助android开发者开发C/C++动态库,并能自动将so和java应用打包成apk
- 我的理解:如果有单独的一些工具如交叉编译器,把so和android应用打包成apk的工具的话,可以不使用NDK,因为JNI机制就可以生成so,而NDK可以理解成:为方便android第三方应用调用本地库(C/C++库)的工具
Android NDK开发有以下几个步骤:
- JNI接口设计
- 使用C/C++实现本地方法
- 生成动态链接库
- 将动态链接库复制到Java工程,运行Java程序
.mk:
- Android.mk文件:指定我们要编译的so文件所包涵的内容.
- Application.mk文件:描述应用程序中所需要的原生模块(静态库与动态库)
so文件包含的都是一些模块,可以是静态库,也可以是动态链接库,只有动态链接库被安装进三方应用后,静态库才能被动态链接库使用.
Android:
- MiniMum Required SDK:最低支持的android api版本,低于这个版本的android手机不能安装应用
- Target SDK:应用最高支持android api版本
- compile with: 哪个版本的android SDK编译你的工程,也就是最适合的的,最原生支持你的应用的android 版本
- 简言之:1:最小;2:最大;3:最适合.
Android应用程序由4个模块构造而成:Activity,Intent,ContentProvider,service;并不是每个应用程序都得有这四个部分。
- Activity: 代表一个用户所看到的屏幕
- Intent:实现Activity与Activity的切换
- content provider:用于不同应用之间共享数据
- service:后台服务(比如用于播放音乐的进程就可以用service实现)
注意: 任何一个应用程序都必须在AndroidManfest.xml文件中声明使用到的这些模块。
C++ and C
为了加深对多态的理解,用c语言实现多态
Reference
C++调用DLL的两种方式
- 隐式链接: 通过使用与DLL对应的lib文件和.h文件来调用DLL文件.
- 显式链接: 通过LoadLibrary和GetProcAddress来实现调用DLL文件.
exp1:
while(*dst = *src)
{
do_somethind;
}
``
*dst = *src`依次完成:赋值、测试赋值、指针递增, 这三个操作组成一个原子操作, 因此while循环执行完后src,dst指向‘\0’的后一位, __该部分看完代码后进一步确定__.``
c的一些技巧 part1:
+ double test = atof("10.5")
+ int test = atoi("10");
+ c不允许函数中定义函数
+ 得到小于等于整数n的,且为2^m的倍数的整数:
int n = 33;//n为任意输入的整数 int m = 2;//m任意值 n = (n»m)«m; 运行后n为:32;
+ n>>=1;//n = n/2;
+ n&m,按位与:同时为1,值才能为1;n|m,按位或:出现1,则为1;n^m,按位异或,只有相反才为1, 异或具有交换律和结合律,由b^(a^b)=>a和a^(a^b)=>b得到一个交换两个整数值而不需要第三个变量的算法,具体实现为:
a = a^b; b = b^a; a = b^a; –split—– int a; int b; int c; if(a == b) c = 1; else c = 0; 这段代码等价写法: c = !(a ^ b)
+ 赋值语句的结合性,自右向左。因此a=b=c=1的执行顺序是:
c=1; b=1; a=1;
+ 外部变量或函数的作用域:从声明开始到文件结束
+ 外部变量:独立于任何函数
+ 外部变量只能在一个文件中定义一次,在其他文件中使用时要加extern声明
+ 头文件存储着共享的东西
+ 用static声明限定外部变量和函数,可以将其后声明的对象的作用域限定为被编译源文件的剩余部分,因而,static限定的变量或函数不会和同一程序中其他源文件中同名的变量或程序冲突
+ static类型的内部变量特点:作用域为本函数,但是不管该函数是否被调用,static类型的内部变量一直存在,eg:
void test(){ static int a = 8; a++; printf(“a:%d\n”,a); } main(){ put(); put(); put(); return 0; } 结果为: a:8 a:9 a:10
+ 变量的声明除了可以紧跟在函数开始的花括号之后,还可以跟在任何符合语句的左花括号之后,这种方式可以隐藏程序块之外的同名变量
+ 不进行显示初始化时,外部变量、静态变量初始化为0,自动变量和寄存器变量的初值为无用信息外部变量和静态变量在程序开始执行前就会被初始化,且他们的初始化必须为常量表达式
+ 预处理器是编译过程中单独执行的第一个步骤
+ *作用于指针:访问指针所指向的对象
+ 数组名代表第一个元素的地址
+ 字符串常量是一个字符数组
+ 二维数组是一种特殊的一维数组,即元素为一维数组
+ 函数的参数如果为二维数组,那么必须指出该数组的列数,行数无所谓
+ 指针数组,放的是指针,如: char *month[] ={"hello","hello1"}.ps:将char和*连起来看,同二维数组相比,指针数组的优点是:数组的每一行长度可以不同
+ 命令行参数:main(int argc,char* argv[]),argc表示运行程序时命令行中参数的个数,第二个参数是一个指向字符串数组的指针`int *a = 5;a`叫做指向整形的指针,`char *month[] ={"hello","hello1"};month`叫做指向字符串数组的指针,可见其叫法可由右侧的初始化类型决定
+ 函数指针可以被赋值,存放在数组中,传递给函数以及作为函数的返回值[5.12复杂声明]
+ malloc
int *t = malloc(10*sizeof(int));
t[0] = 250;t[1] = 251;
int g = *t++;
int gg = *t;
输出:g:250, gg:251
+ struct
struct point {
int x;
int y;
}
+ struct
typedef struct{
int x;
int y;
}Point;
然后用Point直接定义对象 Point p = {3,6};其中typedef的作用为:用来建立新的数据类型名(重命名),如:typedef int length
+ 28. 联合union,目的:一个变量可以合法的保存多种数据类型中任何一种类型的对象。特点:联合是一个结构,它的所有成员相对于基地址的偏移量都为0
typedef union{
char g;
int gg;
float ggg;
double gggg;
}L;
sizeof(L):结果为8,也就是最大类型double的长度
L test;
int a = 250;
float b= 251.8;
test.gg = a;
test.ggg = b;
执行后test.ggg才有意义
结合代码:union的特点是:它是一种动态类型的变量
+ flag
int flag = 0;
flag |= 01 | 02;
将flag的第一位和第二位设置成1(|或运算符)
flag &= ~(01|02)
将flag的第一位和第二位设置成0(&与运算符)
+ 直接访问字中的位字段
typedef struct{
unsigned char a : 2;
unsigned char b : 2;
unsigned char c : 4;
}flag;
sizeof(flag):运行后为:1(即一个字节)
typedef struct{
unsigned char a : 3;
unsigned char b : 2;
unsigned char c;
}flag;
sizeof(flag):运行后为:2(注意内存对齐)
声明为unsigned保证他们是无符号常量
typedef struct{
unsigned char a : 4;
unsigned char :4;
unsigned char b : 2;
unsigned char :0;
unsigned char c;
}flag;
sizeof(flag):运行后为:3( 无名字段 :0 强制在下一个字边界上对齐;无名字段:4起到填充作用)
+ 文本流由一系列的行组成,每一行的结尾都是一个换行符
getchar:从标准输入一次读取一个字符;
while((c = getchar())!= EOF){.....};终端任意输入,然后敲回车,才会进入while循环迭代执行
+ 负数的表示,最高位为0表示正数,最高位为1表示负数,如果整数用n个bit表示,则最高位的权重为-2^(n-1),注意是负的权重,对于其他位置,比如j位(从右记位,起始位为1)权重为2^(j-1),那么最后表示的负数就为各个位置的加权和。eg: int x = -6;则x的二进制表示为: fffffffa,根据上面的计算方法有:-2^31 + 2^30 + 2^29 + ... + 2^3 + 2^1
+ 负数的符号位扩展不影响数的大小,拿上面的例子来说,无论在前面补多少个1,最终的结果仍然是-6,当然最高位为符号位
+ 固定小数点的折算(固定小数点的折算与实现)
+ 37. 编译与链接的原则是:
a. 改了就重新编译: 头文件改了,引用改头文件的c文件也得重新编译
b. 只要有重新编译,就要发生链接
c. makefile 是make进行编译和链接的说明书
target:prerequisite
command
官方解释:
target这一个或多个的目标文件依赖于prerequisites中的文件,其生成规则定义在command中
自己的理解:
prerequisites中如果有一个以上的文件比target文件要新的话,command所定义的命令就会被执行。这就是Makefile的规则。也就是Makefile中最核心的内容。
C语言中应用内存管理有两种方式,一种是系统管理,一种是应用自管理。
+ 系统管理方式是指应用直接使用系统malloc和free函数进行内存申请和释放,由系统管理内存的使用情况。
+ 应用自管理方式一般是使用内存池管理技术,一次性向系统申请应用需要的一大块内存,然后使用内存池把这块内存管理起来。
怎么查看gcc的预处理输出呢?
gcc -E hello.c -o test.c
__含义__ :test.c是预编译后的输出,hello.c是程序员写的源代码. 不管结构体的实例是什么——访问其成员其实就是加成员的偏移量(看testPointer.c)
__注意__ :如果成员是数组,那么访问的是数组的相对地址,如果成员是指针,那么访问的是指针所指向的内容,因此如果实例代码中,如果str的s换成char* s的话,程序会在f.a->s时挂掉。
Puzzle 1(网上整理的, 原始出处记得加引用undone): 此段程序的作者希望输出数组中的所有元素,但是他却没有得到他想要的结果,是什么让程序员和计算机产生歧义?
#include<stdio.h>
#define TOTAL_ELEMENTS (sizeof(array) / sizeof(array[0]))
int array[] = {23, 34, 12, 17, 204, 99, 16};
int main()
{
int d;
for(d = -1; d <= (TOTAL_ELEMENTS-2);d++)
printf("%d\n", array[d+1]);
return 0;
}
__解答__: 运行上面的程序,结果是什么都没有输出,导致这个结果的原因是sizeof的返回值是一个unsinged int,为此在比较int d 和TOTAL_ELEMENTS两个值都被转换成了unsigned int来进行比较,这样就导致-1被转换成一个非常大的值,以至于for循环不满足条件。因此,如果程序员不能理解sizeof操作符返回的是一个unsigned int的话,就会产生类似如上的人机歧义。
+ 宏替换顺序:一个宏的参数是另一个宏,先替换外面的宏,后替换参数。因此#define _ToStr(x) #x以后_ToStr(a+b)相当于"a+b",而#define X a+b 再_ToStr(X)的结果相当于"X"——先替换外面的宏,给X加了引号,再替换里面的宏,对" "内的宏名不替换。
+ 宏替换顺序:一个带参数的宏内部调用另一个宏,参数也是一个宏,则先替换外层的宏,再替换外层宏的参数,最后替换内层宏。因此采用两层转换之后,外边的宏先被替换了,但没有完全展开,然后参数被替换了(保证参数是宏时被展开),最后外边的宏展开。
+ 总之由外向里替换,遇到#要执行;或者:外宏,外参数,内宏,中间任何环节遇到#或者##都要执行,然后看能不能替换,这种说法解答了testHong.c。
Puzzle 2(网上整理的, 原始出处记得加引用undone): 下面这段程序输出什么?
#include<stdio.h>
int main()
{
float f = .0f;
int i;
for(i = 0; i < 10; i++)
f = f + .1f;
if(f == 1.0f)
printf("f is 1.0 \n");
else
printf("f is NOT 1.0 \n");
return 0;
}
__解答__:不要让两个浮点数相比较。所以本题的答案是”f is NOT 1.0″,如果你真想比较两个浮点数时,你应该按一定精度来比较,比如你一定要在本题中做比较那么你应该这么做`if( (f – 1.0f)<0.1 )`
iota(from numeric)
#include
int main () { int numbers[10];
std::iota (numbers,numbers+10,100);
std::cout « “numbers:”; for (int& i:numbers) std::cout « ’ ‘ « i; std::cout « ‘\n’;
return 0; }
模版特化
namespace std
{
template<> struct hash
opencv
- calib3d: 相机校准,和3D内容相关
- core: 非常重要, 矩阵操作, 基础数据类型
- dnn: 神经网络相关
- feature2d: 图像脚点检测、图像匹配
- flann: 和聚类相关的、一些临域算法
- highgui: 界面操作相关的
- imgcodecs, imgproc: 图像处理相关的
- ml: 机器学习模块
- photo: 图片的处理
- stitching: 图片的拼接
position_c: youtubevideo_v1
人脸
- Face detection、stasm proj、Active Shape Models with SIFT Descriptors and MARS、one million paper(dlib proj)
Face detection
人体检测的方法主要分为三类,区别如下:
- 不同特征的使用, 如:边缘特征(受背景杂波影响较大),哈尔特征,梯度特征(SIFT,形状上下文,HOG)
- 不同分类器的选择,如:近邻分类器,神经网络,SVM,Adaboost
- 图像中整体处理和分步处理的区别,整体处理是指将图像的整体区域进行分析和处理,分步处理是指先将图像分成若干小的子区域,先处理每一个子区域,然后通过区域间的关联对图像进行分析
stasm proj
主要Function:
- stasm_search_single: 输入脸,打标记
- stasm_search_auto: 与stasm_search_single作用相同,只不过是处理多脸的情况
stasm可以对一张或者对多张脸进行打标记:
- 输入: 可以设置脸部大小、命令行标记
- 输出: stasm.log(文本文件)[list 77 point(landmarks)
- swas: 比较测量的landmarks和引用的landmarks
minimal2该函数可以对一副图像的多张脸进行landmark,细节可以看stasm lib.h和minimal2.cpp.
stasm_open_image:可以检测出人脸. inputs of stasm_open_image:
- multiface:设置1时,对图像中所有脸进行landmark;设置0时,对图像中最好(最大)的脸进行landmark。
- minwidth:脸部大小(face detector box)占图像宽度的百分比,通常设置未10%,15%
注意, 对于multiface:
- 设置为0时,最好脸可能不是最大的脸(为了缩减false positives,比median过大)或者过小的脸都会被剔除掉
- 设置为1时,一组大小相近的脸会被landmark
- 如果不想移除大小过大或者过小的脸就不调用facedet.cpp中的DiscardMissizedFaces 函数
- 调试时,如果想显示脸部矩形,就设置#define TRACE IMAGES
stasm中的一些功能说明:
- stasm_search_pinned:用户手动在脸上打些点(眼睛,鼻子,嘴巴),然后算法将剩余点补充.
- stasm_convert_shape:将77点图形转化成特定数目点图形(如XM2VTS,BioID格式),新格式的landmark是通过原77点图形计算出来的.
- stasm_force_points_into_image:将landmarks转换成图像边界(boundary),可用于图像切图.
- stasm_printf:可以打印到stdout中,也可以打印到stasm.log中,可以和stasm_init配合使用.
stasm的几个实现细节:
- 如果人脸靠近图像边缘,那么openCV frontal face detection 经常失败,stasm的做法就是在图像的周围添加一个10%的border;如果不想要这个border,就将Facedet.cpp的BORDER_FRAC设置为0
- 为了加快速度,stasm在Hatdesc.cpp中使用了hash_map
- stasm使用了HAT(Histogram Array Transform),HAT用于在landmark时的模版匹配
- 如果想训练新的模型,可以参考Building Stasm 4 Models (http://www.milbo.users.sonic.net/stasm, 2014. )
- 当前的Stasm版本只实现了frontal model(referred to yaw00 model),并不支持3/4 model
- stasm中有一些非线程安全的变量.
- 全局变量有_g后缀,几乎所有的头文件都被stasm.h包含;与example applications 相关的定义全部都放在
appmisc.h中.
Active Shape Models with SIFT Descriptors and MARS
abstract:
- 用简化的SIFT描述子代替ASM中1D gradient profiles,同时用MARS(multivariate adaptive regression splines)用于描述子匹配(descriptor matching),描述子是在landmark周围的
- 论文算法是modified ASM
- SIFT用于模版匹配(template matching)
related work:
- MARS:multiple adaptive regression splines(多元适应性回归样条)
- SIFT和HAT描述子的作用相同
descriptor matching:
- Once we have the descriptor of an image patch, we need a measure of how well the descriptor matches the facial feature of interest(度量描述子对感兴趣区域的匹配).
- SVM可用于descriptor mathching,但是用SVM比较慢,而MARS比SVM快多了,而且结果几乎与SVM一样好。
ASM
ASM是一种基于点分布模型(Point Distribution Model)的算法。
PDM:
PDM中,外形相似的物体,例如人脸、人手、心脏、肺部等的几何形状可以通过若干关键特征点(landmarks)的坐标依次串联形成一个形状向量来表示。对于发生扭曲,旋转,偏移的图形,可用procrustes方法进行归一化。
ref
- 1. Active Shape Models with SIFT Descrip-tors and MARS
- 2. Technical Report: Statistical Models of Appearance for Computer Vision
-
3. Locating Facial Features with an Extended Active Shape Model. ECCV
- 4. Multiview Ac-tive Shape Models with SIFT Descriptors for the 300-W Face Landmark Challenge
ASM笔记
Aligning:
- 移动训练集中的每个样本,使得图像的重心位于原点(即对所有样本使用同一坐标系)
- 选定一个样本(如x0)做为对平均形状x_的初始检测,将x_归一化,并将该初始化检测单独记为x_0
- 将训练集中的所有样本与x_对齐
- 利用已经对齐的形状重新计算x_
- 将x_与初始化检测x_0对齐,并对x_归一化
- 如果不收敛,就跳转到步骤3(收敛条件为:平均形状改变很小)
- ps:具体的将两个形状对齐的算法见附录的详细推导。
- 利用PCA进行将维:
- 应用统计学方法解决模式识别问题经常遇到模式问题,在低纬空间里可以解决的问题在高位空间里往往行不通,因此降维是解决实际问题的关键,PDM中采用的将维方法是常规的PCA,应用PCA进行降维的原理是:选取由训练集构成的高维空间即云团(cloud)的t(t<2n)个主轴做为线性变换,在该线性变换下就可以得到原始高维数据的低维表示,即达到了将维的目的,其中主轴恰好是协方差矩阵的特征向量,通常我们选取大特征值对应的特征向量。详细的PCA推导见附录。
- 对于t的选取,如果问题限定了精度,那么我们就可以通过逐渐增加主轴(协方差矩阵的特征向量)的试探方法来确定t。另外一种策略是选择t个特征向量使得模型能够展现训练样本集给定比例98%的形状变化。该比例可通过:sum(t个特征值)/sum(全部特征值)=给定比例[如98%]确定。
- 利用步骤1所得到的PCA表示模型来对新形状进行适配:
将模型点X向目标点Y(即:目标形状)进行匹配的过程。利用步骤三得到的线性变换可将低维系数b转换为高维的形状,然后再通过尺度变换,旋转变换和移位来对形状进行变换就得到了我们的模型点。将X向Y对齐的过程就是迭代寻找b和变换(尺度,旋转以及移位)的过程,优化目标为最小化X与Y的平方距离,具体的算法流程如下(matching):
- 将低维向量b初始化为0
- 利用变换矩阵将b转换为高维形状(x=x_ + Pb)
- 利用最小二乘法找到当前最好的变换系数(优化目标为最小化X与Y的平房距离,X=T(x))
- 利用步骤3求得的变换系数,求Y在逆变换下的y(y=T’(Y))
- 将y进行规范到与x_同一尺度(y_=y/(y.x_))
- 更新b,即b=P_(y_-x_),[P_代表P的逆,由于P是正交矩阵,因此逆矩阵就是转置矩阵]
- 如果不收敛就跳转到步骤2
如何测试模型
通常采用leave-one-out实验来测试模型的优劣,具体来说,去除数据集中的一个样本,然后利用剩下的样本集合来生成模型,然后用生成模型来对去除的样本进行估计,并记录误差。如果误差过于大,这说明训练集样本量过小;如果误差比较小,也仅仅说明一个类型的图形可能不仅有一个样本,而不能说明训练集是完备的。
小结
ASM是基于点分布模型(PDM)的,其主要特点是用PCA对形状进行建模以及形状适应新图像时梯度方向的移动策略。ASM由两部分构成:训练和搜索。训练主要完成两项工作,即:从训练集中构建形状模型(用于表示形状)、从训练集中构建局部特征(用于适应新图像)。搜索主要完成的工作是:形状X在局部特征的作用下在新图像上移动得到新形状X‘,然后用形状模型表示该新形状X’。此外,在训练和搜索过程都要注意对数据进行标准化。
one million paper(dlib proj)
theory
1.dlib中的初始预测有问题
- “Also, to reproduce the testing scenario, we ran the face detector on the training images to provide an initial configuration of the landmarks (x0), which corresponds to an average shape”
dlib的训练过程中的初始预测是不是不只用样本数据?因为只用样本的初始预测可能表示力不够
SIFT 是在landmark周围抽取的图像特征:
- “SIFT features ex- tracted from patches around the landmarks to achieve a ro- bust representation against illumination”
1.SIFT 是不可导的,因此使用一范数或者二范数方法就需要对jacobian和hessian进行数值近似
- ps:数值近似的计算复杂度非常高
SDM
- SDM的目标就是学习一系列下降方向和尺度变换因子(牛顿方法中hessian干的事)
- SDM不需要SIFT是二阶可导,也不需要对jacobian和hessian进行近似计算;SDM直接通过学习获得形状差和图像特征差之间的线形回归器来直接导出图像特征差的投影矩阵
- SDM就是在牛顿迭代框架下进行建模的,只是去除了对二阶导的限制
expr
Sun Mar 10 13:32:07 CST 2017
训练了帧间回归器,来捕捉前后帧的运动:
- 在真实形状的基础上增加了满足高斯分布的平移和尺寸扰动, 对人脸的平移运动捕捉的比较好,抖动情况也比较好,但是对于人脸的转动,捕捉的不好
- 增加了模拟转动的训练样本(20度,10度),这样训练样本就变成了包含转动和平移的训练样本, 单帧检测的时候效果比较好,也不怎么抖,但是跟踪起来的时候全部都乱了,现在在分析原因
接下来的工作:
- 查找形状乱掉的原因
- 传入小角度的扰动
- 在3D形状基础之上生成平移
- 考虑分类
- 研究基于CLM跟踪的论文和代码:
- 计算语义五点,算姿态,选平均形状,回归(JDA)
Idea
- 递归最小二乘RLS能否做点事
- 笔记中的点子
- 自相关在周期检测中的思想能否做点事
- 考虑overlap-save算法,思考是否能构造相似的重叠数据以避免混叠
- multi scale 下用不同方法重建
- 反卷积网络
- 加方差
- 深度稀疏字典即学习个稀疏变换出来,基于压缩传感
- a pair of face,学习逆函数出来,可以跟压缩传感没关系
- 在动态成像中,如果采样率一直下降,时间分辨率会增加,但是空间分辨率下降,所以考虑在采样过程中插入以及全采的数据,并且一帧低频,一帧高频
转载请注明:Mengranlin » 点击阅读原文